參考資源 · Reference Map
AI 算力供應鏈地圖:七層誰主導、卡脖子在哪、台灣的位置(2026 年中)
從自研晶片、晶圓代工、先進封裝、HBM 記憶體、互連網路、電力資料中心到 CUDA 軟體棧——拆解每一層的主導者、挑戰者、瓶頸,以及台灣卡在哪個環節。
最後更新:2026-06-28 · 矽基前沿 [Si]gnals 持續監測

2026 年中,AI 算力供應鏈呈現一個矛盾:每一家有規模的雲端與模型公司都在做自研加速器要繞過 Nvidia,卻同時把設計押在博通、把製造與封裝押回台積電。真正的瓶頸從「晶片夠不夠快」一路後移到先進封裝(CoWoS 全年售罄)、HBM 記憶體(三強全數售罄)、互連速率、電網併網(FERC 對六大電網下令),最頑強的護城河則停在 Nvidia 近二十年累積的 CUDA 軟體生態。台灣卡在這條鏈最賺、最難取代的中段——先進製程、先進封裝、IC 設計、伺服器組裝、電源散熱幾乎一條龍,HBM、GPU 核心架構、EUV 設備則是三處留白。
一張圖看懂
從晶片到模組:大家都繞回台積電
自研晶片運動想繞過 Nvidia,卻把設計押給博通、把製造與封裝押回台積電。
一眼看懂
八個關鍵事實
- 01 Google Ironwood(TPU v7)於 2026 年 4 月正式上線,單顆 4.6 PFLOPS(dense FP8)、192GB HBM3e、600W,9,216 顆 superpod 達 42.5 ExaFLOPS,由博通設計、台積電代工,首度明確定位「推論優先」。
- 02 Anthropic 同意採購最多約 100 萬顆 Ironwood TPU、五年 5GW 容量,Google 投資最多 400 億美元,其中逾 1GW 於 2026 年上線;Google 開始把 TPU 外賣多家客戶(含 Meta 成外部客戶)。
- 03 博通成為自研 ASIC 的設計樞紐:已確認六大 XPU 客戶,同時承接 Google TPU、OpenAI XPU、Meta MTIA 的矽片實作與整合(SerDes、HBM 控制器、3.5D 封裝、Tomahawk/Jericho 網路)。
- 04 台積電 CoWoS 月產能 2026 年底目標約 12–13 萬片(約 2024 年底 3.5 萬片的近 4 倍),CoWoS-L/S 全數售罄,Nvidia 一家約占 2026 年 CoWoS 總需求 60%;目前 100% 晶片仍運回亞洲/台灣做先進封裝。
- 05 HBM 三強 2026 年全年產能售罄:2026 Q2 SK 海力士約 62%、美光約 21% 超車三星(約 17%);SK 海力士 2026 年 2 月全球率先量產 HBM4,邏輯基底晶片交台積電 12nm 級製程(HBM4E 才規劃改用 3nm),三星則用自家 4nm 廠。
- 06 互連層出現「數字大的速率卡關、可量產的較低速率補位」窗口:448G PAM4 約需 224 Gbaud、功耗過高近乎不可行,商用 400G/lane 光學要到約 2028–2029;聯發科以 224G SerDes 切入 Google TPU v8e(Zebrafish),AI ASIC 營收 2026 約 20 億美元、2027 上看數十億美元。
- 07 電力成為實體瓶頸:FERC 於 2026 年 6 月 18 日依《聯邦電力法》206 條對六大電網(PJM、MISO、SPP、CAISO、ISO-NE、NYISO)發 show-cause 命令;美國高壓變壓器交期拉長至 36–48 個月、部分達 5 年;台電自 2024 年起暫緩桃園以北 5MW 以上資料中心併網。
- 08 高通 2026 年 6 月 24 日宣布以約 39.2 億美元全股票收購 AI 編譯軟體 Modular(預計 2026 下半年完成),補上自研資料中心晶片最缺的 CUDA 替代軟體層;Nvidia 在資料中心 GPU 營收市佔約 86%、CUDA 約 400 萬開發者,切換成本以年計。
核心追蹤
自研 & 商用 AI 晶片對照表
誰在造、給誰用、誰設計、誰代工、進度到哪。
| 公司 | 晶片 | 用途 | 設計/代工 | 狀態 | 報導 |
|---|---|---|---|---|---|
| TPU v7 Ironwood | 推論優先,兼訓練(單顆 4.6 PFLOPS dense FP8、192GB HBM3e、600W) | 設計:博通/代工:台積電 | 2026/4 正式上線量產;已外賣 Anthropic(最多約 100 萬顆)、Meta | 看報導 | |
| TPU 8t(Sunfish)/8i(Zebrafish) | 首次訓練/推論分流:8t 訓練、8i 推論 | 8t 博通、8i 聯發科/代工:台積電 2nm | 2026 下半年起 preview,目標 2027 下半年 GA | 看報導 | |
| Amazon | Trainium3 | 訓練(單顆 2.52 PFLOPS FP8、144GB HBM3e、4.9TB/s) | 自研(Annapurna)/代工:台積電 | 2025/12 re:Invent UltraServer GA、生產矽片 2026 Q1 出貨;Project Rainier 主力;首度宣布外賣;客戶以 Trainium 降本最高 50% | 看報導 |
| OpenAI | XPU(首顆推論 ASIC「Jalapeño」) | 推論為主,規劃 10GW 客製加速器 | 設計:博通、CPU IP:Arm/代工:台積電 3nm/2nm | Jalapeño 2026/6 公布;首批部署目標 2026 下半年;2026/5 傳 180 億美元級融資卡關 | 看報導 |
| Meta | MTIA 300/400/450/500 | 推論(排序推薦+生成式 AI) | 設計:博通(XPU 平台)/代工:台積電 2nm | 2026/4/14 簽多世代協議(至 2029)首階段逾 1GW;MTIA 300 已量產、400 完成實驗室測試、450/500 鎖定影像生成與 LLM 推論、2027 量產 | 看報導 |
| Microsoft | Maia 200(代號 Braga) | 訓練/推論 | 自研/代工:台積電 | 從 2025 延至 2026 量產;設計變更與人力流失(部分團隊流失達五分之一),效能預估落後 Nvidia Blackwell | 看報導 |
| Qualcomm | AI200/AI250 | 資料中心推論(AI200 單卡 768GB LPDDR、機櫃約 160kW) | 自研(Hexagon NPU)/代工:台積電 | AI200 2026 商用、AI250 2027;與沙烏地 HUMAIN 簽 200MW、2026 起部署 | 看報導 |
| Qualcomm | Dragonfly C1000 | 資料中心 CPU(逾 250 核、>5GHz Oryon 架構) | 自研/代工:台積電 | 已簽 Meta 為首位具名客戶(多世代協議),商用 2028;同日宣布 39.2 億美元收購 Modular、並傳洽購 Tenstorrent | 看報導 |
| Nvidia | Vera Rubin(R100) | 商用 GPU 訓練+推論(單顆 50 PFLOPS NVFP4 推論、288GB HBM4、22TB/s) | 商用/代工:台積電 3nm、雙 die chiplet、HBM4 | 已進入量產,合作夥伴產品 2026 下半年上市 | 看報導 |
| AMD | Instinct MI450/MI400 系列 | 商用 GPU 訓練+推論(約 40 PFLOPS FP4、432GB HBM4、19.6TB/s) | 商用/代工:台積電(CDNA 5) | 2026 上市對打 Vera Rubin;MI500 預定 2027 | 看報導 |
| Micron/SK 海力士 | HBM4/HBM4E | 餵 AI GPU 的高頻寬記憶體(邏輯基底晶片改用先進邏輯製程) | 台積電(HBM4 邏輯基底 12nm 級、HBM4E 規劃 3nm);三星用自家 4nm 廠 | SK 海力士 2026/2 全球率先量產 HBM4;三強 2026 全年產能售罄、合約鎖到 2027 並延伸至 2028 | 看報導 |
| 台積電 | CoWoS/CoPoS 先進封裝 | 把運算晶粒與 HBM 整合在同一載板;CoPoS 改用 310mm 方形面板 | Nvidia、AMD、博通等;CoPoS 載板點名群創、Ibiden | CoWoS 全數售罄、2026 年底目標 12–13 萬片/月;CoPoS 2026/6 完成試產線、量產估 2028 下半年–2029 | 看報導 |
| 聯發科 | Google 下一代 TPU(v9/第 8 代)SerDes 與自有資料中心 ASIC | 客製 AI 推論加速器與高速互連 | Google、台積電代工 | 以較成熟 336G SerDes 拿下 Google 下一代 TPU 高速傳輸;ASIC 2026 營收上看 10 億美元、2027 上看占總營收約 20% | 看報導 |
逐層拆解
AI 算力供應鏈的七層
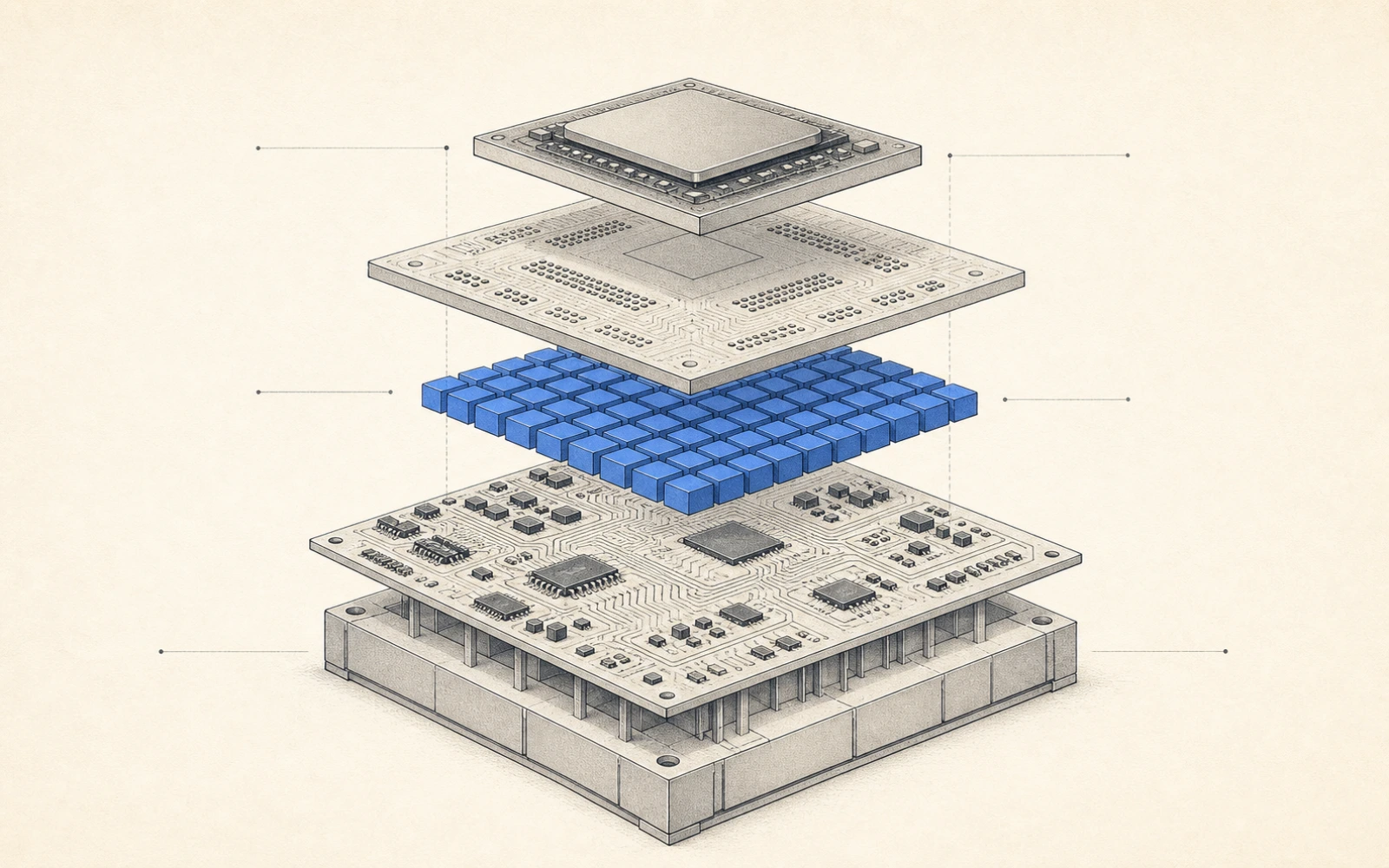
01自研 AI 晶片運動
每一家有規模的雲端與模型公司都在做自己的 AI 加速器,把 Nvidia 從「唯一選項」變成「其中一個選項」——Google TPU 量產第七代並開賣給 Anthropic、Meta;Amazon Trainium3 上線並首次外賣;OpenAI、Meta 都把下一代晶片押在博通的 XPU 平台上;幾乎每一顆都回到台積電投片。
主要玩家: Google TPU、Amazon Trainium / Inferentia、OpenAI(博通 XPU)、Meta MTIA、Microsoft Maia、Qualcomm、Nvidia、AMD
卡脖子:所有自研晶片都繞不開兩個共同瓶頸:設計端高度集中在博通(Google、OpenAI、Meta 的 XPU 都靠它整合 Ethernet/SerDes/封裝),製造端則全部回到台積電投片(含 2nm/3nm 先進製程與 CoWoS/CoPoS 封裝)。換言之,雲端廠想擺脫 Nvidia,卻同時把整個自研運動押在博通+台積電這對組合上;再加上 HBM(美光/SK海力士/三星)2026 年全數售罄,記憶體是第三道閘。
02晶圓代工與先進封裝
AI 晶片做完還不能用——要先進封裝把運算晶粒、HBM 記憶體拼在同一塊載板上。這層由台積電 CoWoS 獨大、台灣後段(日月光、力成、SPIL)與美國艾克爾分流,先進封裝產能是 2026 年整條 AI 算力鏈最緊的瓶頸。
主要玩家: 台積電 TSMC、艾克爾 Amkor、日月光 ASE(含矽品 SPIL)、Nvidia、Intel / Samsung
卡脖子:先進封裝產能(CoWoS/SoIC)是 2026 年 AI 算力鏈最緊的環節。2026 年總需求估近 100 萬片晶圓(2024 年僅約 37 萬片),台積電 CoWoS 線全數售罄,供需缺口從年中約 20% 預計到年底才收斂到約 10%。即使晶片在美國亞利桑那做出來,目前幾乎 100% 仍要運回台灣做封裝——後段產能與良率,而非前段微縮,成了 AI 硬體的真正前線。
03高頻寬記憶體(HBM)
把 DRAM 堆疊成「記憶體高樓」貼著 GPU 放、用最寬的資料通道餵算力的關鍵元件;SK 海力士、三星、美光三強寡占,2026 年全年產能售罄,HBM4 戰場開打,台積電吃下邏輯基底晶片代工。
主要玩家: SK 海力士(SK Hynix)、美光(Micron)、三星電子(Samsung)、Nvidia、台積電(TSMC)
卡脖子:HBM 產能本身就是瓶頸——三強 2026 年全年產能已售罄、合約鎖到 2027 年後,買不到就沒有;且 HBM 每擴一分產能就排擠約三倍的標準 DRAM 晶圓(美光揭露 HBM 對 DDR5 約 3:1 的換算比),把一般記憶體一起推進缺貨與漲價,帳單一路傳到消費端。
04互連與網路
當運算晶片越堆越多,瓶頸從「單晶片多快」變成「晶片之間連得多快」——這一層決定數萬顆 GPU/ASIC 能不能像一台機器一樣協作,NVLink、SerDes、乙太網與光通訊在此交火,而台灣的聯發科與一票光模組廠正卡進關鍵位置。
主要玩家: Nvidia (NVLink / NVLink Fusion)、Broadcom (博通)、Marvell、MediaTek (聯發科)、UALink Consortium / Ultra Ethernet Consortium、台灣光模組與磊晶廠(聯鈞、聯亞、華星光、上詮、波若威等)
卡脖子:兩個並存的卡脖子點。技術面:448G SerDes 用既有 PAM4 調變要做到約 244 Gbaud,功耗與插入損耗過高近乎不可行,可能得改用 PAM6/PAM8 並仰賴 2nm 製程的 DSP,量產要等 2028–2029——這讓「下一代互連到底走多快」整體卡關,反而讓可量產的 224G/336G 成為現實贏家。供應面:光模組往 1.6T 走時,InP 磊晶片與 EML 雷射等關鍵光元件吃緊到 2027,成為擴產的實體瓶頸。
05電力與資料中心
算力供應鏈最終卡脖子不在晶片而在電:美國資料中心電力缺口逼出 FERC 命六大電網替 AI 讓路、台灣則暫緩桃園以北大型資料中心併網並對大用戶分時計價,電與併網成為 2026 年中真正的瓶頸。
主要玩家: FERC(美國聯邦能源管理委員會)、PJM / MISO 等六大區域電網(RTO/ISO)、Constellation / Entergy / Kairos 等電力與核能業者、台電(台灣電力公司)、國科會 / 經濟部能源署
卡脖子:電力供給與電網併網。瓶頸已從資本與 GPU 供給移到實體電力基礎設施:美國變壓器交期拉長到 3–5 年、開關設備(switchgear)排到 2028 年售罄;2026 年美國新增資料中心產能僅約三分之一在實際興建,其餘卡在「已宣布、未動工」。台灣則卡在北部供電裕度與地方阻力導致電力建設延宕,桃園以北大型資料中心併網被暫緩。
06軟體棧與 CUDA 護城河
AI 算力供應鏈最頑強的卡脖子不在矽,而在軟體:Nvidia 用近二十年累積的 CUDA 生態(約 400 萬開發者、cuDNN/cuBLAS/TensorRT、整套編譯與除錯工具)把非 Nvidia 晶片擋在門外,挑戰者(Modular/Mojo、AMD ROCm、OpenAI Triton、PyTorch torch.compile)正從「寫一次、到處跑」的抽象層往上撬這道牆。
主要玩家: Nvidia CUDA、Modular(Chris Lattner)、高通 Qualcomm、AMD ROCm、OpenAI Triton、PyTorch(Linux Foundation)
卡脖子:CUDA。卡脖子不在能不能做出對等晶片,而在近二十年沉澱的軟體生態與切換成本:cuDNN/cuBLAS/TensorRT 等預最佳化函式庫、約 400 萬開發者的肌肉記憶、除錯工具、訓練教材,以及埋進生產程式碼裡的大量 CUDA-specific 最佳化。即使 ROCm 7 性能逼近、Triton 能跨硬體出 kernel,「寫一次、到處跑」要在生產級可靠度上真正追平,仍是以年計的工程戰。
07台灣在 AI 算力供應鏈的位置
台灣卡進 AI 算力供應鏈最賺、最難取代的中段——先進製程代工、先進封裝、IC 設計、伺服器組裝、電源散熱幾乎全包,是「非紅供應鏈」的事實主幹;但記憶體(HBM)、GPU/加速器架構設計、EUV 設備這三層留白,仍靠美韓荷供給。
主要玩家: 台積電 TSMC、日月光 ASE / 矽品 SPIL、聯發科 MediaTek、鴻海 Foxconn / 廣達 Quanta / 緯創 Wistron / 英業達 Inventec、緯穎 Wiwynn、台達電 Delta / 光寶 Lite-On
卡脖子:台灣同時握有兩個全球級卡脖子點:台積電的先進製程+CoWoS 先進封裝(2026 全年售罄、Nvidia 一家吃掉約五到六成配額),以及全球約九成 AI 伺服器組裝產能高度集中在台灣與台廠手中——這種集中度既是議價力,也是地緣風險本身。
瓶頸
卡脖子在哪
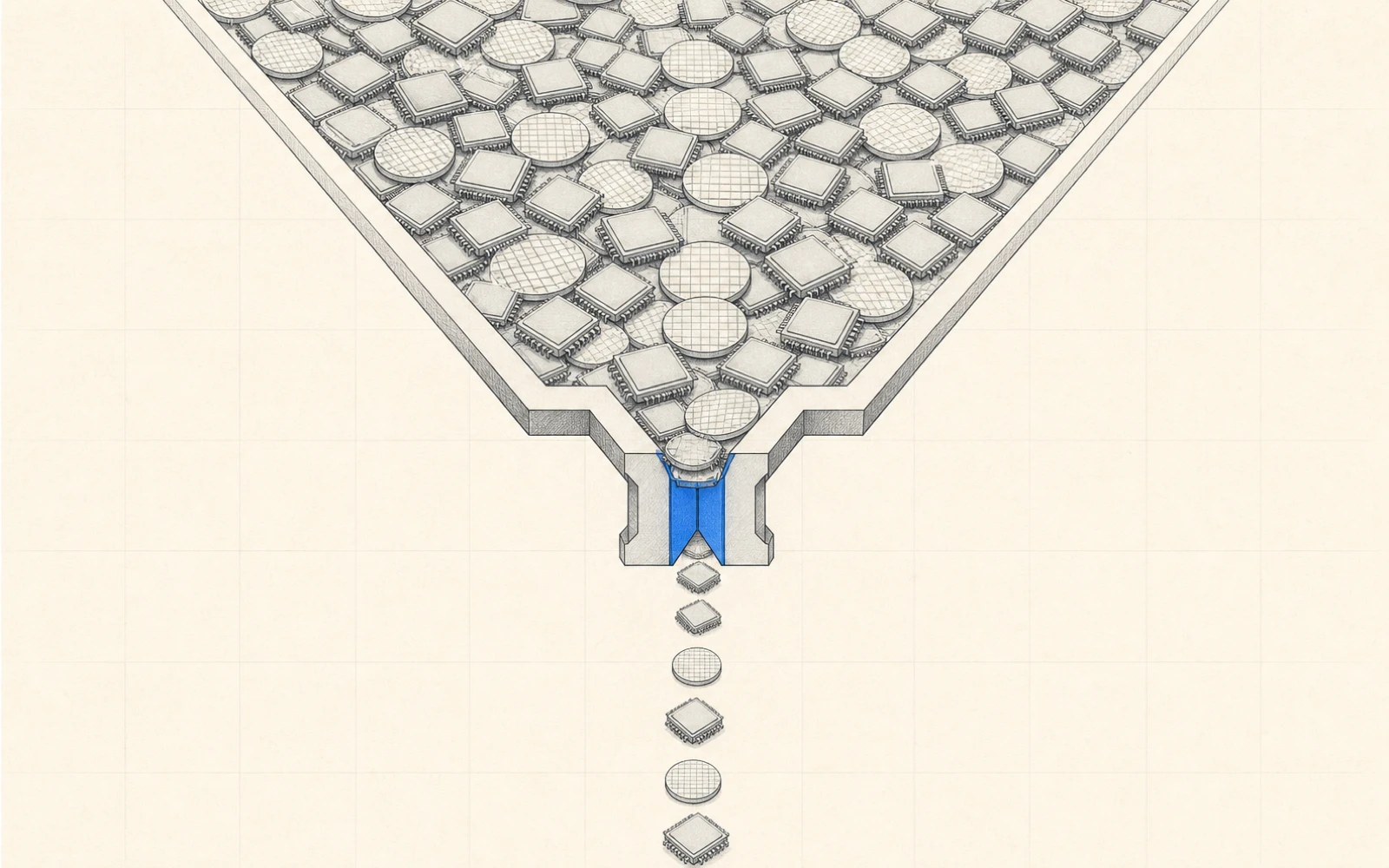
博通:自研 ASIC 的設計樞紐
Google TPU、OpenAI XPU、Meta MTIA 的矽片實作與整合(SerDes、HBM 控制器、3.5D 封裝、Ethernet 網路)都繞回博通;雲端廠想擺脫 Nvidia,卻把整個自研運動押在同一家設計夥伴上。
關鍵方:Broadcom(博通),客戶含 Google、OpenAI、Meta 等六大 XPU 客戶
台積電先進製程:自研與商用晶片的共同投片點
幾乎每一顆 ASIC(TPU、Trainium、XPU、MTIA)與商用 GPU(Vera Rubin、MI450)最終都在台積電投片,N3/N2 先進製程是共同節點;2026 Q1 台積電晶圓代工市佔約 72%,N2 訂單排到 2027 下半年至 2028。
關鍵方:TSMC(台積電)
先進封裝 CoWoS/SoIC:2026 年最緊的環節
高階 AI 加速器近乎只有台積電 CoWoS 能接,2026 年總需求估近 100 萬片晶圓(2024 約 37 萬片),CoWoS-L/S 全數售罄,缺口由年中約 20% 到年底才收斂到約 10%;目前 100% 晶片仍運回亞洲/台灣封裝。
關鍵方:TSMC 主導,OSAT 由日月光、矽品、艾克爾分接;最大需求方 Nvidia 約占 60%
HBM 記憶體:三強全數售罄+擠壓標準 DRAM
HBM 三強 2026 年全年產能售罄、合約鎖到 2027 並延伸 2028,買不到就沒有;HBM 每擴一分產能排擠約三倍標準 DRAM(HBM3E 對 DDR5 約 3:1),把一般記憶體一起推進缺貨漲價。
關鍵方:SK 海力士(約 62%)、美光(約 21%)、三星(約 17%)
互連速率:448G 卡關、可量產速率補位
448G 用 PAM4 約需 224 Gbaud,功耗與插入損耗過高近乎不可行,商用 400G/lane 光學要到約 2028–2029;下一代互連整體卡關,反讓可量產的 224G/336G 成為現實贏家。
關鍵方:Broadcom、Marvell、聯發科(SerDes);NVLink/UALink/UEC 標準陣營
電力與電網併網:算力鏈的最終天花板
瓶頸從資本與 GPU 移到實體電力:美國變壓器交期 36–48 個月、2026 年新增資料中心產能僅約三分之一在實際興建;FERC 對六大電網下 206 條命令、台電暫緩桃園以北 5MW 以上併網。
關鍵方:FERC、PJM/MISO/SPP/CAISO/ISO-NE/NYISO(美國);台電、國科會、經濟部(台灣)
CUDA 軟體棧:最頑強的非矽護城河
卡脖子不在能否做出對等晶片,而在近二十年沉澱的 cuDNN/cuBLAS/TensorRT、約 400 萬開發者的肌肉記憶與生產程式碼裡的 CUDA 最佳化;即使 ROCm 7 性能逼近、Triton 能跨硬體出 kernel,生產級追平仍以年計。
關鍵方:Nvidia(資料中心 GPU 營收市佔約 86%);挑戰者 Modular(高通)、AMD ROCm、OpenAI Triton、PyTorch
台灣在哪
台灣卡在這條鏈的哪幾層
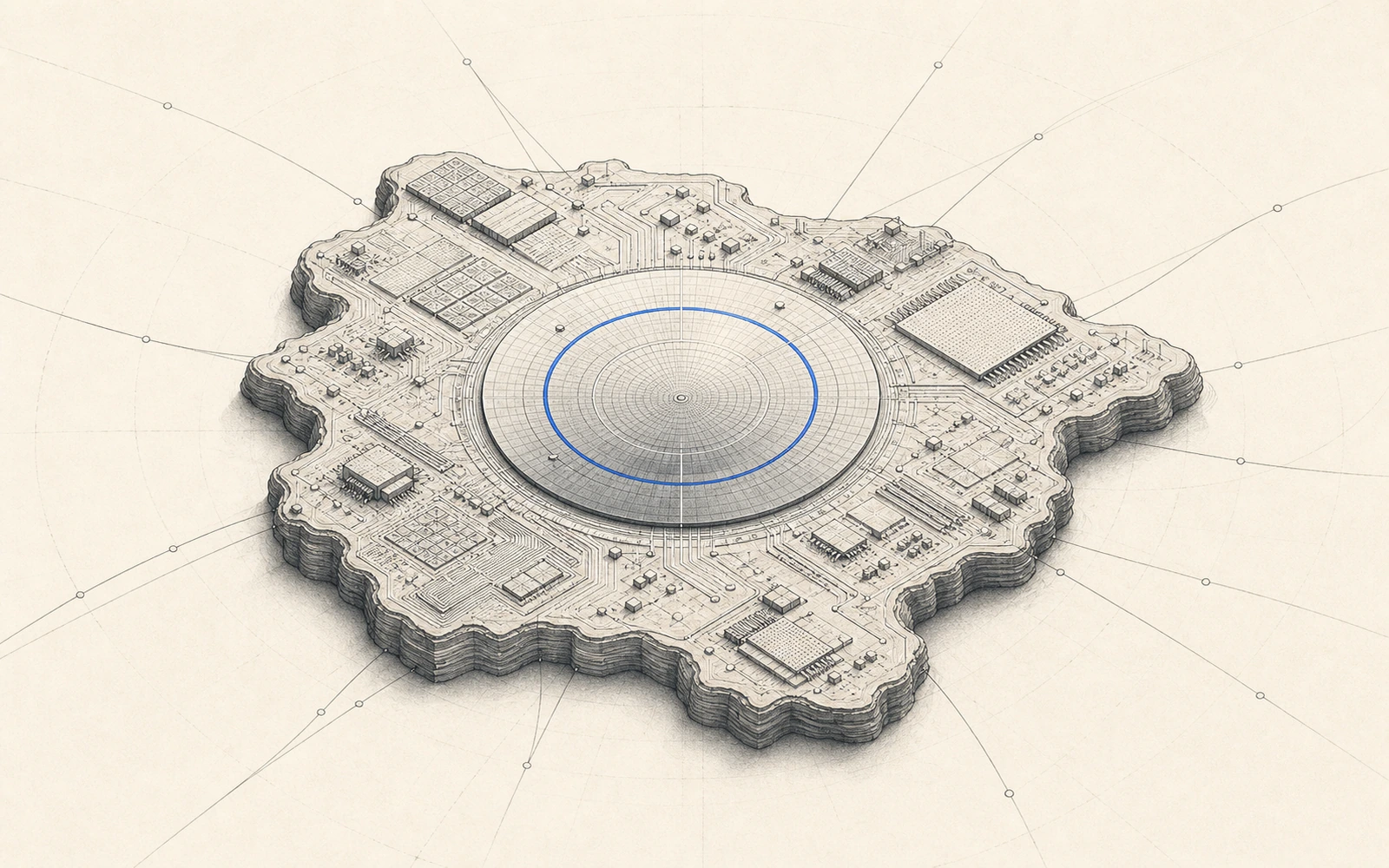
台灣卡進 AI 算力供應鏈最賺、最難取代的中段,並在多層同時握有全球級節點。自研晶片運動「逃不掉的後段」:幾乎每一顆 ASIC 與商用 GPU 最終都在台積電投片(2026 Q1 晶圓代工市佔約 72%),N3/N2 與 CoWoS/CoPoS 先進封裝是共同節點,後段 OSAT 又由日月光、矽品、力成主導,全球 AI 晶片幾乎都要「回台灣封一次」。聯發科罕見從手機 SoC 切進雲端 ASIC,以較成熟的 336G SerDes 拿下 Google 下一代 TPU 高速傳輸、並以 224G 切入 v8e(Zebrafish),ASIC 2026 營收上看 10 億美元、2027 上看占總營收約 20%。HBM 出現新命門:HBM4 起的邏輯基底晶片改用先進邏輯製程,SK 海力士(台積電 12nm 級、HBM4E 規劃 3nm)與美光都交台積電,只有三星留在自家 4nm 廠——台灣不做 DRAM 顆粒,卻在 HBM4 世代成為三強裡兩強的共同代工命脈。伺服器端,鴻海、廣達、緯創、英業達合計掌握全球逾九成 AI 伺服器產能(鴻海機櫃組裝約 40%),三雄 2025 年營收均破兆元台幣,並成美系雲廠「去風險」產線移往墨西哥/北美的主幹;台達電供 Nvidia Vera Rubin 平台 800VDC 機櫃電源(單櫃達 1.1MW、效率達 98%)與 3MW 液對液 CDU,電源散熱是第二條成長曲線。互連光層也有實質供應:CPO 的 3D 整合靠台積電 COUPE/SoIC 平台,世芯(GUC)把 Ayar Labs 光引擎接進其 ASIC 與先進封裝流程,聯亞等供應 InP 雷射磊晶(2026 Q1 營收年增近 99%)。軟體棧這層台灣幾乎缺席——定義「非 Nvidia 晶片能否真被用起來」的權力落在 Modular(高通)、AMD、OpenAI、PyTorch 社群手上。三處明顯留白:HBM(靠 SK 海力士、三星、美光,經濟部以約 3.18 億美元補貼引美光在台做 HBM 研發)、GPU/加速器核心架構設計(Nvidia、AMD 主導,聯發科多為協同設計)、以及最上游的 EUV 曝光機(ASML 獨家)。Nvidia 黃仁勳 2026 年 5 月稱台灣為「AI 革命震央」、宣布每年在台投資約 1,500 億美元;AMD 同年 5 月宣布逾 100 億美元台灣生態系投資,官方點名 ASE、SPIL 為夥伴。電力則是自身擴張的天花板:台電暫緩桃園以北 5MW 以上資料中心併網、分流中南部並對大用戶採三段式時間電價(夏月尖峰約 9.39 元/度、約離峰 3.7 倍),國科會估 2029 年全台 AIDC 約 450MW。
常見問題
FAQ
誰在自己造 AI 晶片?
2026 年中,幾乎每一家有規模的雲端與模型公司都在做自研 AI 加速器:Google(TPU v7 Ironwood)、Amazon(Trainium3)、OpenAI(與博通的 XPU、首顆 Jalapeño)、Meta(MTIA)、Microsoft(Maia)、Qualcomm(AI200/AI250)。但設計多繞回博通、製造幾乎全回台積電投片——自研運動把 Nvidia 從「唯一選項」變成「其中一個選項」,卻同時押注博通+台積電。
AI 算力供應鏈最大的瓶頸(卡脖子)在哪?
瓶頸已從「晶片夠不夠快」後移到四處:先進封裝(台積電 CoWoS 2026 全年售罄)、HBM 記憶體(SK 海力士/美光/三星三強全數售罄)、互連速率(448G 卡關),以及電力與電網併網(美國 FERC 對六大電網下令、台電暫緩桃園以北併網)。最頑強的非矽護城河則是 Nvidia 近二十年累積的 CUDA 軟體生態。
台灣在 AI 算力供應鏈的位置是什麼?
台灣卡在這條鏈最賺、最難取代的中段:先進製程代工(台積電 2026 Q1 晶圓代工市佔約 72%)、先進封裝(CoWoS/CoPoS)、IC 設計(聯發科切進 Google TPU)、伺服器組裝(鴻海/廣達/緯創掌全球逾九成 AI 伺服器產能)、電源散熱(台達電)幾乎一條龍。三處留白:HBM、GPU/加速器核心架構、EUV 曝光設備。
大家都在自研晶片,為什麼還離不開 Nvidia 和台積電?
兩道護城河:軟體上,Nvidia 的 CUDA 有約 400 萬開發者與埋進生產程式碼的最佳化,切換成本以年計;製造上,幾乎每一顆自研 ASIC 與商用 GPU 最終都在台積電投片、用台積電 CoWoS 封裝。雲端廠想擺脫 Nvidia 的晶片,卻擺脫不了台積電的製造與 CUDA 的生態。
延伸閱讀
相關深度報導(23)
- Amazon 第一次說要把 Trainium 賣到 AWS 之外:直接踩進 Nvidia 的生意,代工仍在台積電
- 數字大的這次輸了:Google 下一代 TPU 的高速傳輸,傳由聯發科以較成熟的 336G SerDes 拿下
- 最大的 Nvidia 買家之一,自己做了一顆晶片:OpenAI 與博通發表首顆客製推論 ASIC「Jalapeño」
- Qualcomm Dragonfly C1000 是什麼?高通資料中心 CPU 簽下 Meta,同日 39 億美元收購 Modular
- 高通傳出價最高百億美元,要買下 Jim Keller 的 AI 晶片新創 Tenstorrent
- 算力之爭打到軟體層:高通收購 Modular,連 LLVM 之父一起買進資料中心
- 一座 AI 資料中心年電費 13 億美元,折舊卻是六倍:鴻海劉揚偉把 Vera Rubin 的帳算給你看
- 後段也要搬一份去亞利桑那:台積電與艾克爾簽十年先進封裝約,日月光在台擴產接招
- 台積電方形晶圓封裝 CoPoS 是什麼?把圓晶圓載板換成 310 公釐方形面板,6 月 22 日進驗證線
- 「專利蟑螂」咬上台積電:本月美國 ITC 初裁,可能擋下 7 奈米以下晶片進口
- 韓股記憶體崩盤的隔天,美光交出 415 億美元創紀錄財報:高頻寬記憶體 2026 年全部售罄
- AI 機房把記憶體吃光,帳單寄到消費者手上:蘋果、微軟同日漲價
- 輝達授權走技術、挖走創辦人——半年後 Groq 募 6.5 億美元換血重建
- 等五年變九十天:美國能源監管機構命六大電網替 AI 資料中心讓路
- AI 進入 classified networks 後,真正賣的是控制面
- GLM-5.1、Kimi K2.6、DeepSeek V4、MiniMax M2.7:四個架構,同一個 SWE-bench 天花板,四條不同的帳單
- Inference 是什麼?機器學習裡「推論」就是訓練好的模型實際算出答案
- 賣 AI 晶片到中國本來不算犯罪:台灣研擬把它列為刑事罪,對象從黑名單擴大到全中國
- 台灣 AI 公司全景圖:誰拿到錢、誰賣掉、誰還活著
- 台灣 AI 島:我們只有晶片,還是也有應用機會?
- 台積電帶動台股融資餘額創 2000 年來新高、槓桿全球最高,一檔占大盤四成
- 美國商務部長擔心一台 EUV 流進中國,ASML 全盤否認:『連專用零件都沒運過』
- 從做螢幕到蓋算力——鴻海把夏普正式接進自己的 AI 硬體版圖
資料來源
權威來源(40)
- Google: Ironwood TPU and the age of inference
- TechCrunch: Google to invest up to $40B in Anthropic in cash and compute
- Amazon: Trainium3 UltraServers now available
- Anthropic: Anthropic and Amazon expand compute partnership
- Tom's Hardware: OpenAI, Broadcom to co-develop 10GW of custom AI chips
- Broadcom (GlobeNewswire): Extended partnership with Meta on custom MTIA silicon
- Tom's Hardware: Meta reveals four new MTIA chips built for AI inference
- DataCenterDynamics: Microsoft delays production of Maia AI chip to 2026
- DataCenterDynamics: Qualcomm launches AI200 and AI250 rack-scale inference
- Nvidia Newsroom: Rubin platform AI supercomputer
- TechPowerUp: AMD positions Instinct MI400 against Nvidia Vera Rubin
- DataCenterDynamics: Qualcomm Dragonfly C1000 CPU set to be deployed by Meta
- TrendForce: TSMC CoWoS supply-demand gap narrowing from 20% to 10% by end-2026
- Amkor IR: TSMC and Amkor announce long-term partnership
- CNBC: TSMC, Nvidia, advanced packaging, Intel
- TrendForce: TSMC advances panel-level packaging CoPoS pilot line
- Astute Group: SK Hynix holds 62% of HBM, Micron overtakes Samsung
- TrendForce: SK Hynix weighs TSMC 3nm for HBM4E logic dies
- TechTimes: Nvidia Vera Rubin enters full production, HBM4 suppliers named
- Nvidia Developer Blog: Inside the Nvidia Rubin platform
- Broadcom IR: Now shipping world's first 102.4 Tbps switch in production (Tomahawk 6)
- ServeTheHome: Broadcom Tomahawk 6-Davisson 102.4T CPO switch shipping
- TrendForce: SerDes wars heat up — Broadcom, Marvell, MediaTek battle for AI interconnect
- HPCwire: Upscale AI eyes late 2026 for scale-up UALink switch
- Tom's Hardware: First TSMC COUPE optical connectivity (Alchip/GUC and Ayar Labs)
- FERC: Aggressive targeted action to speed large-load integration
- Utility Dive: FERC, DOE, data center interconnection
- Berkeley Lab: Report evaluates increase in electricity demand from data centers
- 報導者: 資料中心用電需求(台電北部限電、能源管理法子法)
- Network World: Qualcomm's $3.9 billion purchase of Modular
- Spheron: OpenAI Triton kernel GPU cloud 2026
- Silicon Analysts: AMD vs Nvidia AI GPU market share 2026
- CNBC: Qualcomm data center CPU, Meta
- Mark Lapedus: TSMC gains foundry share in Q1 2026
- Silicon Analysts: Foundry allocation status Q1 2026
- The Diplomat: Taiwan is rewiring North America's AI hardware chain
- AMD Newsroom: AMD announces more than $10 billion in Taiwan ecosystem investment
- Tom's Hardware: Micron secures $318 million Taiwanese subsidy for HBM R&D
- TrendForce: ASE to break ground on six new plants in 2026, CPO mass production
- TechNews: 聯亞光電 2026 Q1 財報(AI 資料中心矽光子需求)
WEEKLY [SI]GNALS
訂閱《矽基前沿週報》
每週五早上,總編輯親自寫的本週 AI 重要訊號 + 台灣視角。
5 個值得知道的訊號 · 1 個產品/模型動態 · 1 個總編判斷 · 5 分鐘讀完。