買不到 Fable 5,就指揮買得到的模型:Sakana Fugu 的繞行解法
7B『工頭』調度買得到的模型跑分領先,卻輸給調度不到的 Fable 5
重點一:2026 年 6 月 22 日,東京 Sakana AI 公開 Fugu/Fugu Ultra——一個自己幾乎不解題、專門調度一池前沿模型的語言模型,指揮 Opus 4.8、Gemini 3.1 Pro、GPT-5.5 與自身實例,包成單一 OpenAI 相容 API。 重點二:在可公開取得的對手中,Fugu Ultra 於四項 coding benchmark 領先——SWE-Bench Pro 73.7、TerminalBench 2.1 82.1、LiveCodeBench 93.2、Humanity’s Last Exam 50.0,贏過 Opus 4.8、GPT-5.5 與 Gemini 3.1 Pro。 重點三:但受出口管制、未公開的 Fable 5 與 Mythos 不在它的調度池內;據獨立報導,Fugu Ultra 的 SWE-Bench Pro 仍低於 Fable 5。Sakana 把產品定位成「不受出口管制」的前沿能力與「AI 主權」工具。
Anthropic 最強的兩個模型,Fable 5 和 Mythos Preview,你買不到。它們鎖在出口管制後,沒有公開的 API 可以接。
2026 年 6 月 22 日,東京實驗室 Sakana AI 對全球端出的回應,是賣你一個專門指揮「你還買得到的那些模型」的模型。
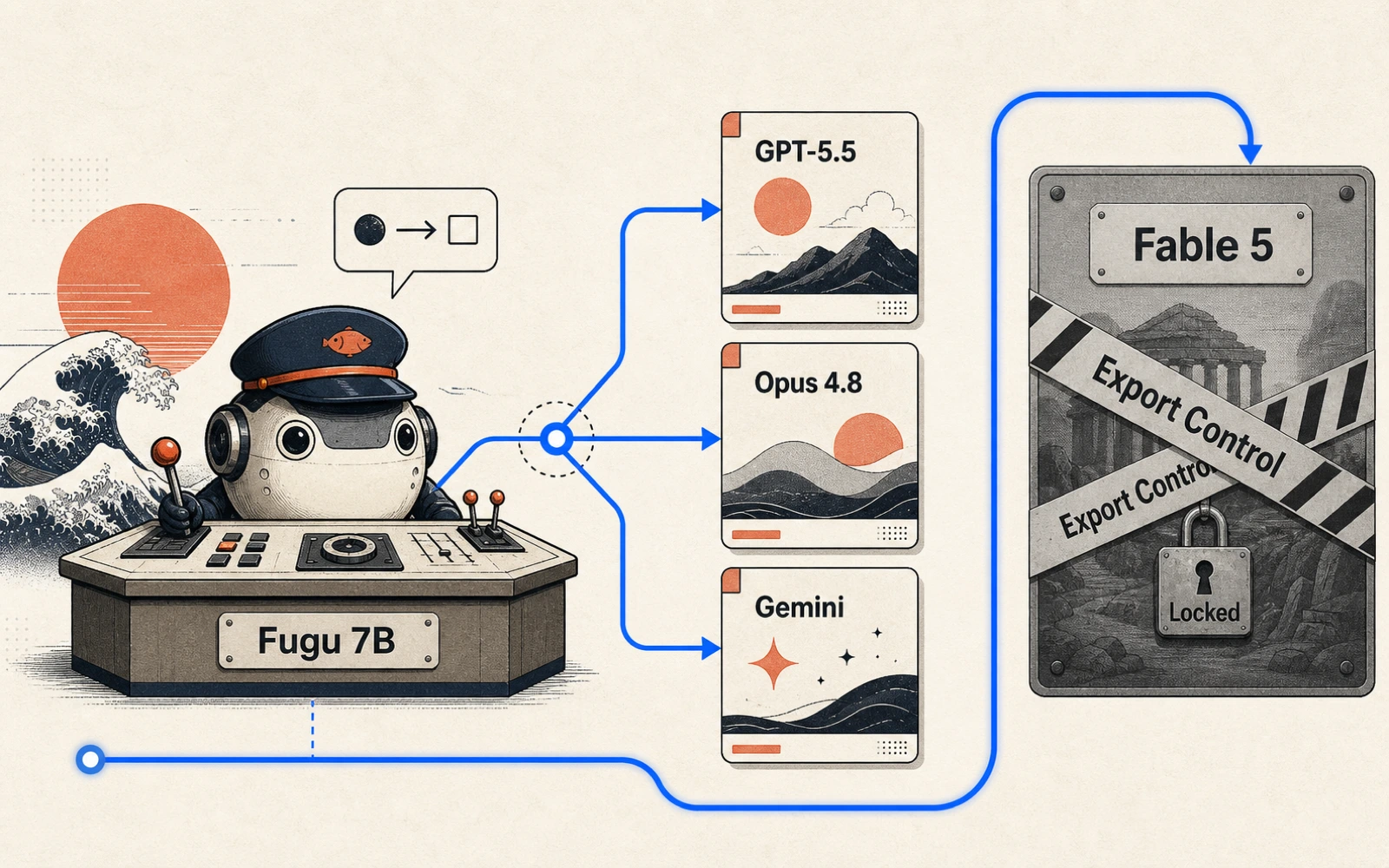
它叫 Sakana Fugu。它本身幾乎不解題,做的事是判斷該找誰、把活派出去、再把結果收回來驗證合成。它指揮的對象,是 OpenAI 的 GPT-5.5、Google 的 Gemini 3.1 Pro、Anthropic 的 Opus 4.8,外加它自己的多個實例。Sakana 把這套東西包成一個 OpenAI 相容的 API,宣稱在工程、科學與推理的硬指標上,整體和 Fable 5、Mythos Preview 並肩——而後面這兩個,正好是它指揮不到的。一頭巨獸把所有事自己扛完,跟一個調度者把活分給一池模型再收攏,是兩種完全不同的取得前沿能力的方式。
一個自己不寫程式碼的模型,怎麼交差?
傳統印象裡的前沿模型是一頭巨獸:參數越堆越大,一個模型把所有事自己扛下來。Fugu 走的是另一條路。據發布期報導,扛起調度的核心只有約 7B 參數的規模,它的工作描述更像工地的工頭:自己不一定下場,但知道哪一段該交給誰。
Sakana 官方頁的說法是,Fugu 拿到任務後「自行決定怎麼處理:夠簡單就直接解,需要更多火力時就組一支專家模型的隊伍並協調它們」。這套協調建立在 Sakana 兩篇 ICLR 2026 論文上——Trinity 用一個輕量的協調器替模型分派 Thinker、Worker、Verifier 的角色;Conductor 則用強化學習,讓系統自己摸索出用自然語言協調的策略。
實際跑起來,當你對 Fugu 送出一道難題,背後可能是 GPT-5.5 先想、Opus 4.8 動手、另一個實例回頭驗證,最後由 Fugu 把結果合起來交還給你。你只看到一個 API、一個回答。
為什麼它對標的兩個模型,剛好不在它指揮的名單上?
Fugu 的池子裡有 Opus 4.8、Gemini 3.1 Pro、GPT-5.5,唯獨少了 Anthropic 帳面上更強的 Fable 5 和 Mythos Preview。Sakana 給的理由很直白:這兩個「未公開可取得(not publicly accessible)」,所以進不了池。
這正是整件事的關鍵背景。Fable 5 與 Mythos 被鎖在出口管制與限定取得的門檻後,連 Sakana 自己也只能拿它們當對標、調度不到。Sakana 把這層限制翻成賣點——官方文案寫的是,Fugu「在不受出口管制風險下交付前沿能力」,並把產品定位成一種「AI 主權」工具,讓組織「藉由調度全世界的模型」取得更高的營運與地緣安全。
對拿不到 Fable 5 的人來說——這份名單上也包括台灣的團隊——Sakana 提供的選項,是繞過那道牆,去指揮牆這一側還拿得到的模型。
贏過誰,又輸給誰?
把分數攤開看,Fugu Ultra 在可公開取得的對手裡確實領先。據 VentureBeat 整理的成績:
| Benchmark | Fugu | Fugu Ultra | Opus 4.8 | Gemini 3.1 Pro | GPT-5.5 |
|---|---|---|---|---|---|
| SWE-Bench Pro | 59.0 | 73.7 | 69.2 | 54.2 | 58.6 |
| TerminalBench 2.1 | 80.2 | 82.1 | 74.6 | 70.3 | 78.2 |
| LiveCodeBench | 92.9 | 93.2 | 87.8 | 88.5 | 85.3 |
| Humanity’s Last Exam | 47.2 | 50.0 | 49.8 | 44.4 | 41.4 |
四項 coding benchmark,Fugu Ultra 都站上第一;GPT-5.5 只在 MRCRv2 一項以 94.8 對 93.6 領先。光看這張表,工頭模式贏過了它指揮的每一個成員。
兩件事要放在旁邊一起讀。第一,這些分數有出處差異——Sakana 官方註明,除了 Fugu 自己的成績,其餘都由各模型供應商自報;Fable 5 與 Mythos 若兩個分數都有,取其中較大值。這是一場廠商自報的擂台,沒有第三方統一複測。
第二,也是更關鍵的一條:Sakana 對標的 Fable 5,並沒有出現在上面這張表裡,因為它不在池內。而據 VentureBeat 的報導,Fugu Ultra 的 headline 分數 SWE-Bench Pro 73.7,在贏過 Opus 4.8、GPT-5.5 與 Gemini 3.1 Pro 的同時,仍低於 Fable 5。Sakana 說的「並肩」,是十一項 benchmark 攤平後的整體口徑;落到最硬的那一項程式碼測試,它調度出來的成績,還沒追上那個它調度不到的模型。
「這只是一個 router 嗎?」
Fugu 一公開,社群最先冒出來的質疑就是這句:它有沒有自己的能力,還是只是把別人的模型轉接起來、包一層殼?
幾個現有事實落在這個問題的兩邊。一邊,Fugu 的每筆查詢究竟調度了哪些模型、怎麼分工,對使用者是隱藏的——每筆查詢的選模選擇保持隱藏,路由邏輯屬於 Sakana 的專有部分,你付錢買的是結果,看不到中間的調度。另一邊,產品形態做得相當實:單一 OpenAI 相容 API,免換 SDK;分兩檔——Fugu 平衡效能與低延遲、還能讓你關掉特定 agent,Fugu Ultra 則固定一套池子衝最高品質,model ID 是 fugu-ultra-20260615;每次請求即時回報 token 用量與花費,讓你盯著帳單跑。發布時,已經有接近 500 名早期用戶用過 beta。
router 與否的爭論短期不會有定論。可以確定的是,Sakana 賣的是調度本身——它把「怎麼把一池模型用得更好」這件事,做成了一個你可以直接下單的 API。發布頁把適用場景指向工程、科學、研究、資安與資料分析,特別點名長而複雜的工作流,例如程式碼審查與資安評估裡的持續一致性——這類任務要的是跑得久、前後不走樣,正好是調度多個模型、彼此驗證的長處所在。至於更大的單體模型,這次它沒有端出。
一個自己幾乎不解題、靠指揮別人交差的系統,在買得到的模型裡跑分領先,卻在 SWE-Bench Pro 上止步於 Fable 5——那道把 Fable 5 鎖起來的牆,正是它整個產品想繞過的東西。
資料來源:Sakana AI(Fugu release)、VentureBeat、TestingCatalog。
SOURCES
- A Sakana Fugu: One Model to Command Them All
- B No Claude Fable 5? No problem: Sakana achieves frontier performance with new Fugu multi-model auto synthesis system
- B Sakana AI releases Fugu Ultra system to rival top AI labs
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- AI 戰爭
- Key claims
-
- Sakana Fugu 是一個被訓練來調度其他模型的語言模型,拿到任務後自行決定直接解、或組一支專家模型隊伍協調完成;模型池含其自身的多個實例、Anthropic Opus 4.8、Google Gemini 3.1 Pro 與 OpenAI GPT-5.5。
- Anthropic 的 Fable 5 與 Mythos Preview 不在 Fugu 的調度池內,官方理由是它們『未公開可取得』;Sakana 仍以這兩者為對標,宣稱整體並肩。
- 在可公開取得的對手中,Fugu Ultra 於 SWE-Bench Pro 73.7、TerminalBench 2.1 82.1、LiveCodeBench 93.2、Humanity's Last Exam 50.0 領先 Opus 4.8、GPT-5.5、Gemini 3.1 Pro。
- 據獨立報導,Fugu Ultra 的 SWE-Bench Pro 分數仍低於未進池、受出口管制的 Fable 5——並肩是整體口徑,不是每項都贏。
- Fugu 以單一 OpenAI 相容 API 提供,分 Fugu 與 Fugu Ultra(model ID fugu-ultra-20260615)兩檔;每筆查詢的選模路由對使用者隱藏,每次請求即時回報 token 用量與花費。
- Entities
- Sakana AI · Sakana Fugu · Fugu Ultra · Anthropic Fable 5 · Mythos Preview · Anthropic Opus 4.8 · Google Gemini 3.1 Pro · OpenAI GPT-5.5
- Taiwan relevance
- medium
- Confidence
- medium
- Last updated
- 2026-06-23
- Canonical URL
- https://signals.tw/articles/sakana-fugu-orchestration-routes-export-controls/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
矽基前沿 · AI 戰爭線(編輯:廖玄同),《買不到 Fable 5,就指揮買得到的模型:Sakana Fugu 的繞行解法》,矽基前沿 [Si]gnals,2026-06-23。https://signals.tw/articles/sakana-fugu-orchestration-routes-export-controls/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.