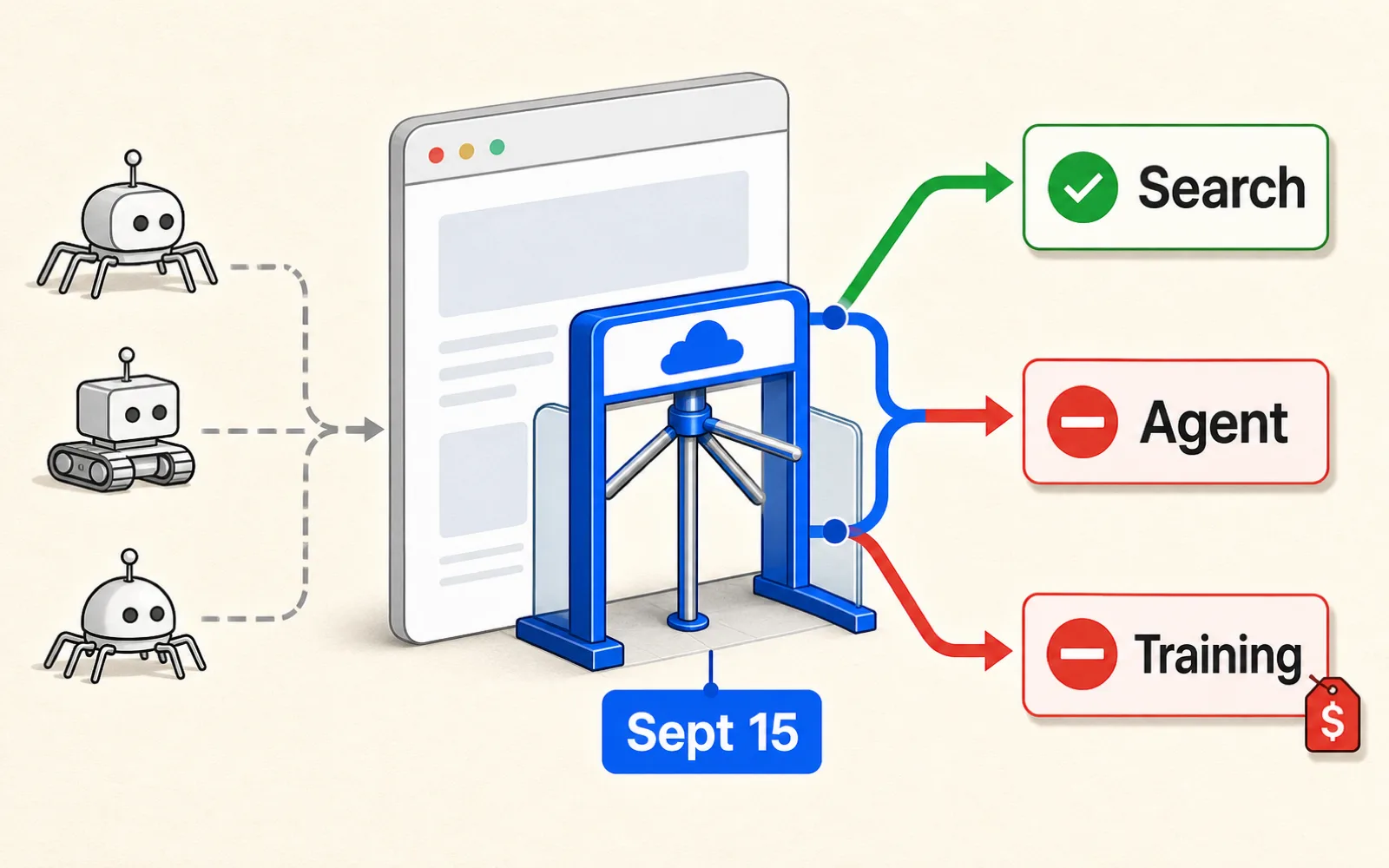
AI 爬你的網站,Cloudflare 讓你分三種處理:搜尋放行、訓練和代理可擋可收費,9/15 起有廣告的頁面預設擋
「要不要讓 AI 抓」從一個開關,變成三個
本文由 AI 協助研究與起草,矽基前沿編輯部編修,總編輯廖玄同審閱定稿。 編輯方針與 AI 使用說明
重點一:2026 年 7 月 1 日,Cloudflare 把「要不要讓 AI 抓內容」從單一開關,拆成 Search(搜尋)、Agent(代理)、Training(訓練) 三類,可各自放行、封鎖或收費。 重點二:自 9 月 15 日起,對「有顯示廣告」的頁面,Training 與 Agent 類預設封鎖、Search 維持放行,套用到新客戶、既有客戶的新網站、以及所有既有免費方案客戶;混合爬蟲(如 Googlebot)以最嚴規則判定。 重點三:收費從 Pay Per Crawl(按每次抓取)往 Pay Per Use(內容被用進 AI 生成的答案才收費)推,初期夥伴 Ceramic.ai、You.com——仍在早期。
到 9 月 15 日,如果你的網站掛著廣告、又用 Cloudflare,有一批 AI 爬蟲會被預設擋在門外——但不是全部。差別在於,Cloudflare 現在把「AI 爬蟲」拆成了三種,分開處理。
過去網站主對 AI 抓內容大多只有兩個粗糙選項:全開,或用 robots.txt 全擋。Cloudflare 7 月 1 日的改動,是把這個單一開關換成三個:來搜尋、會把流量帶回來的放行;拿去訓練模型的、以及即時代使用者去抓的 agent,可以分開擋掉或收費。同一批爬蟲,第一次能按「它要拿你的內容做什麼」來區別對待。
這件事值得每個有網站、做內容、或自己寫 agent 去抓網頁的人今天看一眼:它動到的是「AI 怎麼用你的內容、你能不能分類放行或收錢」的預設規則。下面把三類講清楚、把 9/15 會被動到誰列出來,再分成三種人各自該檢查什麼。
9/15 到底會發生什麼?先看這個預設變化
Cloudflare 這波最有時效性的一條:自 2026 年 9 月 15 日起,對「有顯示廣告」的頁面,Training 與 Agent 類爬蟲會被預設封鎖,Search 類維持預設放行。
Cloudflare 給的邏輯是——頁面上掛廣告,代表這頁是設計給人來看、可以被變現的落地頁,所以預設擋掉「不會帶人回來、只是把內容吸走」的訓練與代理爬蟲,保留會帶引用與流量回來的搜尋爬蟲。
這個預設不是對全網生效,套用範圍是三種:新加入 Cloudflare 的客戶、既有客戶新增的網站、以及所有既有的免費方案客戶。免費方案、頁面又掛廣告的網站,9/15 之後預設值就會變;付費方案的既有網站維持你原本的設定,要自己去後台調。
這套預設背後有一個 Cloudflare 反覆講的判斷:撐了大約 30 年的那套默契——「你讓我的爬蟲抓,我把流量帶回來給你」——已經不成立,因為近期 bot 流量首度超越真人流量。這波動作,就是它想把這套交換重新寫一次。
Search、Agent、Training 差在哪?一張表看懂三類爬蟲
三類的分法,關鍵在「它拿你的內容要做什麼、會不會給你回報」。以下定義與預設,皆取自 Cloudflare 官方說明:
| 類別 | 它在做什麼 | 典型例子 | 9/15 起在「有廣告頁」的預設 | 你怎麼決定 |
|---|---|---|---|---|
| Search(搜尋) | 收集、索引你的內容,以便日後回答關於它的問題,通常會帶回引用與導流 | 傳統搜尋引擎索引 | 放行 | 想要被搜尋到、拿導流 → 放行 |
| Agent(代理) | AI 即時代使用者去把一件事做完 | chat 抓取、browser-use 代理 | 封鎖 | 不想被即時抓走、又沒有回報 → 擋或收費 |
| Training(訓練) | 把你的內容拿去訓練或微調模型、被永久吸收進模型架構 | 模型訓練爬蟲 | 封鎖 | 不想被拿去訓練 → 擋,或談授權收費 |
這張表的重點是:Search 會把人帶回你的網站,另外兩類通常不會。訓練是把內容一次性吸進模型、之後跟你無關;代理是替某個使用者當下抓走答案,使用者不一定會點進你的頁面。Cloudflare 的預設,就是照「有沒有帶流量回來」這條線切的。
Googlebot 這種混合爬蟲怎麼算?以最嚴規則為準
麻煩的是,很多爬蟲不只做一件事。Googlebot、Applebot、BingBot 這類「混合用途」爬蟲,可能同時做搜尋索引和訓練資料收集。
Cloudflare 的處理方式是:混合爬蟲依它的所有行為判定,以最嚴(most restrictive)的規則為準。實際效果——你若選擇擋訓練,那些同時會拿去訓練的混合爬蟲也會被一起擋掉,即使它同時也做你想要的搜尋索引。
這帶出一個真實取捨,尤其是做 SEO 或靠搜尋流量的網站要先想清楚:擋掉訓練,可能連帶影響某些混合爬蟲對你的搜尋索引或 AI 搜尋引用。這是一個要自己權衡、甚至實測的取捨,官方沒有保證擋訓練不會動到你的曝光。要「擋 AI 拿去訓練」還是「保住被搜尋引用的機會」,得看你的流量主要靠哪一邊。
從「按抓取收費」到「按被引用收費」:Pay Per Crawl 與 Pay Per Use 差在哪?
擋之外,另一條路是收費。Cloudflare 原本就有 Pay Per Crawl:一個讓網站對 AI bot 每次抓取收費的市集——爬蟲要抓你的內容,就付一次錢。
這次的方向,是把它往 Pay Per Use 推:讓內容擁有者在內容真正產生價值時才收費,也就是你的內容被用進了 AI 生成的答案,而不是只要被抓下來就計費。兩者差在計費的觸發點:
- Pay Per Crawl:AI bot 抓取你的頁面 → 收費(按次抓取)。
- Pay Per Use:你的內容被用進 AI 給出的答案 / 搜尋結果 → 收費(按實際使用)。
初期合作夥伴公開的有兩家:Ceramic.ai 與 You.com——當你的內容出現在 Ceramic 的 AI 搜尋結果、或 You.com 存取付費內容時,publisher(內容出版方)可以獲得分潤。這條路仍在早期,目前就這兩個夥伴,還不是全面可用的機制,別把它當成馬上能開來收錢的水龍頭。
9/15 前你該檢查什麼?分三種人各自的清單
把上面收束成可以今天就做的動作,看你是哪一種:
如果你做內容、媒體或 SEO:
- 去 Cloudflare 後台看你現在的 AI bot 設定,確認 9/15 的新預設會不會動到你(免費方案+掛廣告頁最容易被動到)。
- 想清楚「擋訓練」和「保住被 AI 搜尋引用」哪個對你更重要——因為混合爬蟲以最嚴規則判定,兩者可能得取捨。
- 若考慮收費,去看 Pay Per Crawl/Pay Per Use,但知道它還早期、夥伴有限。
如果你是一般網站主或電商:
- 確認你有沒有掛廣告的頁面——那是 9/15 預設封鎖 Training/Agent 的觸發條件。
- 決定你要不要讓 agent 抓(例如比價、客服代理會即時抓你的頁面)——擋掉可能少了一些 AI 導購來源,放行則內容被即時取走。
如果你自己寫 agent(browser-use/抓網頁):
- 你的 agent 會被歸為 Agent 類,9/15 起在有廣告的頁面可能被預設擋——測試你的 agent 在目標站點還取不取得到內容。
- 別假設「以前抓得到、以後就抓得到」;把「目標站可能開始擋或要求付費」當成要處理的情況。
最後兩個邊界先記著:這一切只影響用 Cloudflare 的網站,沒用 Cloudflare 的站不受這套預設約束;而且封鎖與收費的實際執行力、AI 公司會不會乖乖付費,目前還沒有成效數據。方向已經很清楚——AI 存取內容從「全開或全擋」變成「分類、可計價」;但它能不能真的讓內容被公平回報,還要看接下來幾個月誰真的付了錢。
資料來源:Cloudflare 官方部落格「Your site, your rules: new AI traffic options for all customers」、「Introducing pay per crawl」、TechCrunch、Engadget。
SOURCES
- A Your site, your rules: new AI traffic options for all customers
- A Introducing pay per crawl: Enabling content owners to charge AI crawlers for access
- B Cloudflare's new policy pushes AI companies to pay for publishers' content
- B Cloudflare will filter out web crawlers that serve AI companies
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- AI 戰爭
- Key claims
-
- 2026-07-01,Cloudflare 把 AI 爬蟲流量管理從單一「擋不擋 AI」開關,拆成 Search、Agent、Training 三個依用途分類、可各自放行/封鎖/收費的類別。
- 三類定義:Search 是收集或索引內容以便日後回答問題(通常會帶回引用與導流);Agent 是 AI 即時代使用者去把一件事做完(如 chat 抓取、browser-use 代理);Training 是把內容拿去訓練或微調模型、內容被永久吸收進模型架構。
- 自 2026-09-15 起,對有顯示廣告的頁面,Training 與 Agent 類爬蟲預設封鎖、Search 維持預設放行,套用到新客戶、既有客戶的新網站、以及所有既有免費方案客戶。
- 混合用途爬蟲(同時做搜尋與訓練,如 Googlebot、Applebot、BingBot)依其所有行為判定、以最嚴規則為準;若網站選擇擋訓練,這些混合爬蟲也會一併被擋。
- Cloudflare 把收費從 Pay Per Crawl(按每次抓取向 AI bot 收費)往 Pay Per Use(內容被用進 AI 生成的答案才收費)演進,初期合作夥伴為 Ceramic.ai 與 You.com。
- Entities
- Cloudflare · Pay Per Crawl · Pay Per Use · Ceramic.ai · You.com · Googlebot
- Taiwan relevance
- medium
- Confidence
- high
- Last updated
- 2026-07-03
- Canonical URL
- https://signals.tw/articles/cloudflare-ai-crawler-pay-per-use/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
矽基前沿 · AI 戰爭線(編輯:廖玄同),《AI 爬你的網站,Cloudflare 讓你分三種處理:搜尋放行、訓練和代理可擋可收費,9/15 起有廣告的頁面預設擋》,矽基前沿 [Si]gnals,2026-07-03。https://signals.tw/articles/cloudflare-ai-crawler-pay-per-use/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.