Anthropic 拆了 40 萬次 Claude Code:贏的不是最會寫的人,是最懂問題的人
新手 15%、專家 28–33%,差距不在會不會寫程式
重點一:Anthropic 用約 40 萬次 Claude Code 真實工作階段的數據回答「AI 寫程式會不會取代人」——被歸類為新手的階段只有約 15% 達「可驗證成功」,中階到專家升到 28–33%。
重點二:差距幾乎不落在「是不是工程師」這條軸上。在會產出程式碼的階段,十大職業群的成功率全擠在彼此約七個百分點內;律師、會計也在用。
重點三:分工線很清楚——人做約 70% 的規劃決策(做什麼),AI 做約 80% 的執行決策(怎麼做)。
兩個數字先擺在這裡:在 Anthropic 的數據裡,被歸類為新手的工作階段,只有約 15% 達到「可驗證成功」;換成懂這個任務的人,成功率跳到 28–33%。
這組數字出自 2026 年 6 月 16 日 Anthropic 發表的研究《Agentic coding and persistent returns to expertise》。它以隱私保護方式,分析了 2025 年 10 月到 2026 年 4 月間、約 23.5 萬人、約 40 萬次的 Claude Code 互動工作階段——也就是人坐在終端機前,把任務交給 AI 代理人(AI agent)去寫、去改、去跑的真實場景。
先講清楚這兩個數字不證明什麼:它衡量的是單一會話內能不能拿到可驗證的成果,不是這段程式碼最後在現實中被採用、被部署,還是被丟掉。把這條界線記著,再往下看就不會把結論放大。
這份研究在量什麼?「可驗證成功」不是嘴上說成功
多數關於 AI 寫程式的討論卡在「感覺有沒有比較快」。這份研究換了一個比較硬的指標。
Anthropic 把一次工作階段算「可驗證成功」,要同時滿足兩件事:一是分類器判定這次會話達成了目標;二是有硬證據佐證——一筆相符的 git commit 或合併的 PR、一組通過的測試,或使用者明確說「對,就是這樣」。少了硬證據,光是看起來完成不算。
在這把尺下:
- 新手的工作階段,約 15% 達可驗證成功,77% 至少部分完成。
- 中階到專家的工作階段,升到 28–33% 可驗證成功,91–92% 至少部分完成。
懂這個任務的人,拿到「有證據的成功」的機率是新手的兩倍多。而這裡的「專家」不是看職稱——下一節會看到,它指的是對手上這個問題的理解。
為什麼贏的是最懂問題的人,不是最會寫的人?
最反直覺的一張表,是把成功率拆到職業別之後,差距幾乎消失了。
在會產出程式碼的工作階段裡,軟體職業的可驗證成功率約 30–34%,非軟體職業約 26–29%——十大職業群全落在彼此約七個百分點之內。「是不是軟體工程師」這條軸,並沒有把成敗拉開多大。
研究點名的非軟體用法很具體:律師寫腳本來標記合約裡缺漏的條款,會計用 Python 跑對帳規則;成長最快的非軟體族群是管理、銷售、法律。他們不是去跟工程師比誰程式寫得漂亮,而是把自己最懂的那塊業務,交給代理人去執行。
所以 Anthropic 把「領域知識」定義成任務層級,而不是職稱層級。它的分類器看三件事:使用者把指令講得多精準、會要 AI 驗證什麼、以及——是使用者在糾正 AI,還是 AI 在糾正使用者。懂問題的人,會把要做的事拆清楚、會指定「做完要怎麼確認對不對」,於是代理人替他做的每一步都踩在點上。
人與 AI 的分工線畫在哪?規劃歸人、執行歸 AI
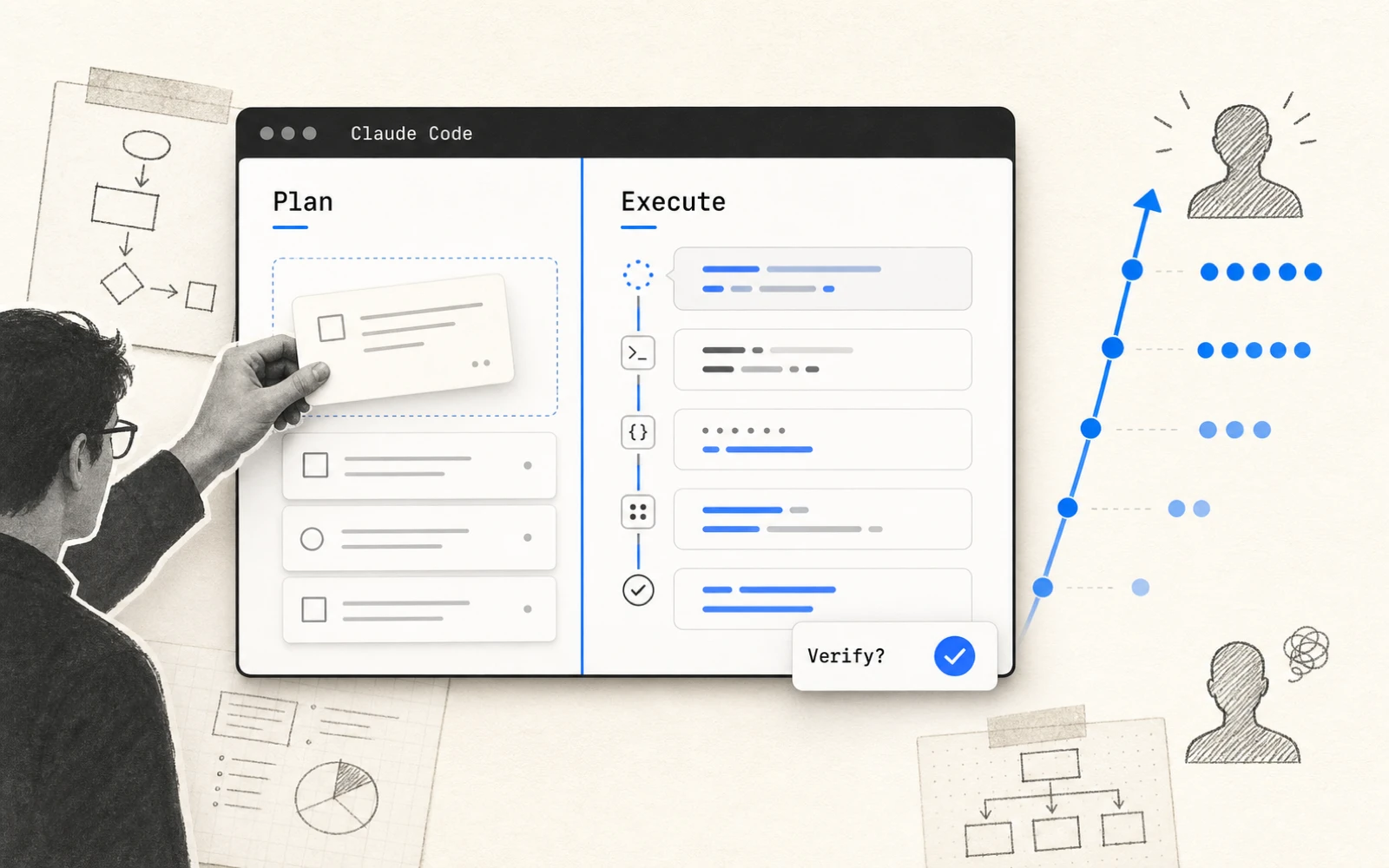
研究用一句話概括了人機分工:人決定做什麼,AI 決定怎麼做。
攤成數字:在一次典型的工作階段裡,使用者做了約 70% 的規劃決策,卻只做 20% 的執行決策——剩下的執行交給代理人。判斷要解什麼、要往哪走,留在人這邊;怎麼一步步把它寫出來,落到 AI 那邊。
懂與不懂的差別,也寫在行為裡:
| 新手 | 中階到專家 | |
|---|---|---|
| 一個指令觸發的動作 | 約 5 個 | 約 12 個(逾兩倍) |
| 一個指令帶出的輸出 | 約 600 字 | 約 3,200 字(約五倍) |
| 卡關時放棄的比率 | 約 19% | 約 5–7% |
專家的一句指令,能讓代理人跑更長的動作鏈、產更多東西,因為他把脈絡與目標一次講足了。遇到卡關,新手放棄的比率約是專家的三倍——懂問題的人更知道怎麼把卡住的地方繞過去,而不是直接關掉視窗。
這份報告能用在哪?四個交辦前用得上的訊號
研究本身不替任何人做決定。但它的數據可以整理成幾個對知識工作者具體的訊號:
- 槓桿在「誰最懂這題」,不在「誰最會寫」。 同一個任務交給懂業務的人、由代理人執行,成功率不輸交給工程師。要產出品質,先想清楚這題在你的團隊裡誰理解最深。
- 把「要驗證什麼」講出來,是專家和新手的分水嶺。 研究裡,懂的人會指定做完該怎麼確認對不對。交辦時附上驗收條件(哪個測試要過、哪份輸出要對得上),代理人才有得對齊。
- 規劃留給人。 數據顯示人主要的價值落在「做什麼」這一端(約七成規劃決策)。把時間花在拆清楚問題,而不是盯著它怎麼一行行寫。
- 卡關不等於不適合。 新手放棄率高,但部分完成率其實有 77%。多數階段不是全有全無,遇阻時把問題重新框一次,常常還能往前推。
這些是報告數據長出來的觀察,不是「你該不該去學寫程式」的處方——那一題留給你自己,看你的角色與團隊怎麼配。
這份研究沒告訴你的事:三條必須一起記的邊界
把報告當成事實來用之前,三條邊界要一起記著,而且多半是 Anthropic 自己標的。
這是自家產品的用量數據。 數字來自 Claude Code 的真實會話,Anthropic 既是出題者也是受益者。它測得到「用我的工具時,懂問題的人表現更好」,但這不等於對所有 coding agent 都成立。
只衡量會話內,不追蹤現實結果。 「可驗證成功」看的是會話當下有沒有 commit、測試或使用者認可;那段程式碼最後有沒有真的被用、還是被丟掉,研究說它無法得知。
排除了量很大的非互動式用量。 研究只看人坐在前面一來一往的互動式階段,把批次、自動化那類非互動式用法排除在外——而那部分的分布可能很不一樣。
至於最容易被拿來延伸的「persistent returns(持續回報)」——Anthropic 的詮釋是這個優勢會自我增強:越會用、抽到越多價值、用得越多。但研究並沒有斷言更強的模型不會把新手和專家的差距抹平;它說會繼續觀察,若哪天專家的溢價開始下降,那代表模型開始供應使用者目前自己提供的判斷。這是觀察中的問句,不是結論。
把這幾條放回最前面那兩個數字旁邊:下次要把一個任務丟給代理人之前,先問一句——這題誰最懂、他講不講得出「做完要怎麼驗證」。報告能幫你問到這裡;剩下的,數據沒替你決定。
資料來源:Anthropic Research《Agentic coding and persistent returns to expertise》(2026-06-16)、TIGZIG、AI Weekly、Crypto Briefing。
LEARN
想系統性學會,不只看這一則?
用 Claude Code 完成真正的工作
讓 Claude Code 在你的專案裡完成一個真實任務,而且控得住權限、驗得了 diff、管得住成本。
從第 0 課開始 →SOURCES
- A Agentic coding and persistent returns to expertise (Anthropic Research)
- B Anthropic's Claude Code Expertise Study (TIGZIG)
- B Anthropic: Domain Expertise Beats Coding Background (AI Weekly)
- B Anthropic releases economic research on Claude Code usage (Crypto Briefing)
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- 工作現場
- Key claims
-
- 2026 年 6 月 16 日,Anthropic 發表研究《Agentic coding and persistent returns to expertise》,以隱私保護方式分析 2025 年 10 月至 2026 年 4 月間約 23.5 萬人、約 40 萬次 Claude Code 互動工作階段。
- 被歸類為新手的工作階段只有約 15% 達「可驗證成功」(77% 至少部分完成),中階到專家升到 28–33%(91–92% 至少部分完成),專家達可驗證成功的機率是新手的兩倍多。
- 研究將「可驗證成功」定義為兩條件並存:分類器判定成功,且有硬證據——相符的 git commit 或 PR、通過的測試,或使用者明確認可。
- 在會產出程式碼的工作階段,軟體職業可驗證成功率約 30–34%、非軟體職業約 26–29%,十大職業群全落在彼此約七個百分點內;決定成敗的是任務層級的領域知識,而非寫程式背景。
- 人機分工是「人決定做什麼、AI 決定怎麼做」:使用者做約 70% 的規劃決策,只做 20% 的執行決策。
- Anthropic 自陳邊界:研究只在會話內衡量、無法得知程式碼最後是否被採用或丟棄,且排除量很大的非互動式用量。
- Entities
- Anthropic · Claude Code · Zoe Hitzig · Peter McCrory
- Taiwan relevance
- medium
- Confidence
- high
- Last updated
- 2026-06-22
- Canonical URL
- https://signals.tw/articles/anthropic-coding-expertise-study/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
林子睿(編輯:廖玄同),《Anthropic 拆了 40 萬次 Claude Code:贏的不是最會寫的人,是最懂問題的人》,矽基前沿 [Si]gnals,2026-06-22。https://signals.tw/articles/anthropic-coding-expertise-study/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.