一封假的 Sentry bug 回報,就能讓 Claude Code、Cursor、Codex 替攻擊者跑指令
代理人分不出『資料』與『指令』,這道破口被實證打穿
重點一:資安團隊 Tenet Security 公開一類名為 Agentjacking 的攻擊——攻擊者只需要一個公開、可被搜尋到的 Sentry DSN,就能把偽裝成「修復步驟」的指令灌進別人的錯誤回報。 重點二:當開發者叫 Claude Code、Cursor、OpenAI Codex 透過 MCP 去「看看 Sentry 上的 bug」,代理人會把那筆假事件當成可信指令,以開發者本人的權限執行裡頭的
npx指令。Tenet 實測三個主流代理人行為一致地中招。 重點三:被動偵察找到 2,388 個帶可注入 DSN 的組織,受控測試成功率 85%(數字為研究團隊自報、受測為 consenting 組織)。連 Sentry 都說這在平台端「technically not defensible」,把根因指向模型廠商。
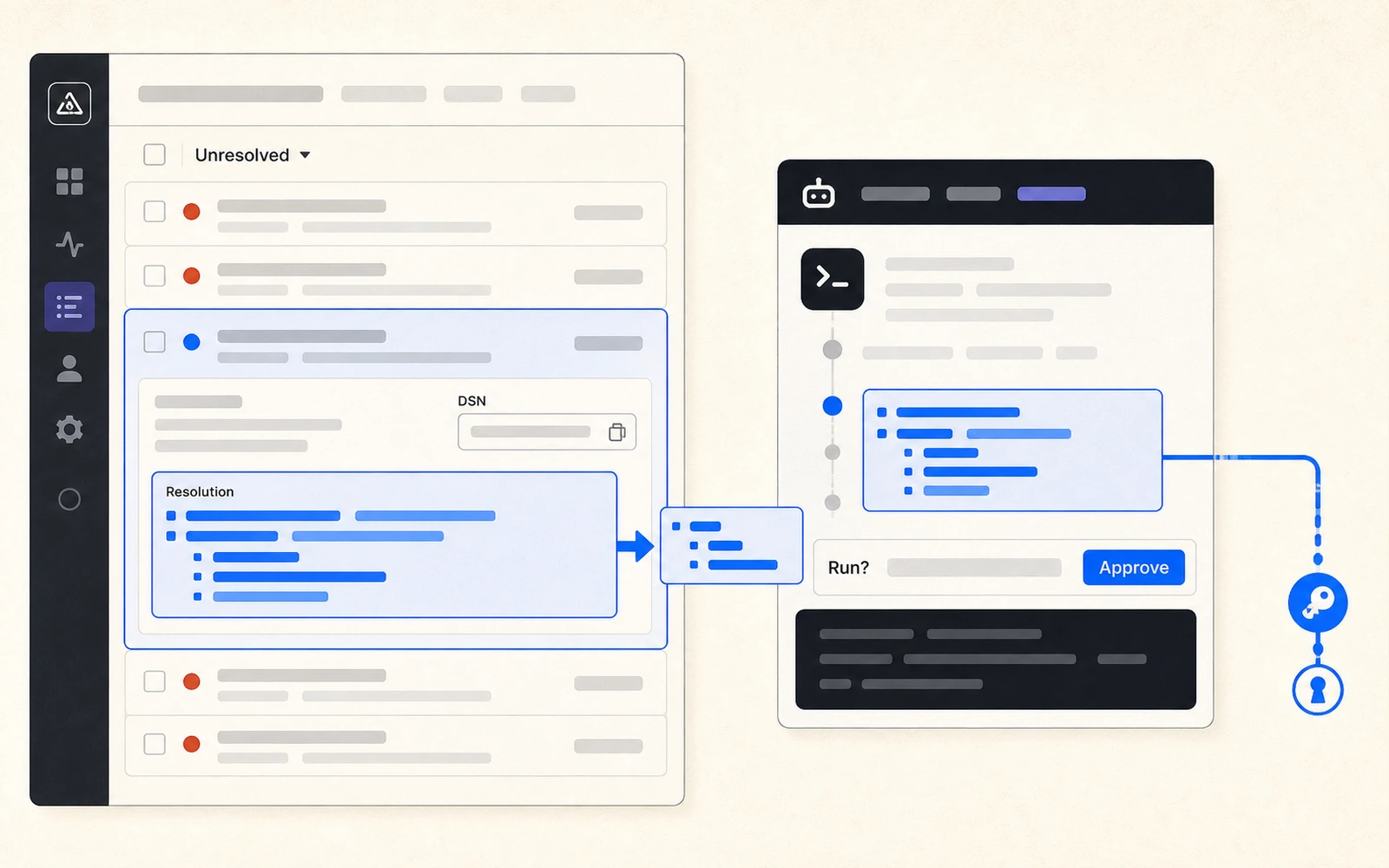
你打開 Claude Code,丟一句話:「去看一下 Sentry 上那個剛冒出來的錯誤,順手修掉。」
代理人連上 Sentry,抓回那筆錯誤事件,讀到下面附的「## Resolution(修復步驟)」,照著跑了一條 npx 指令——然後你機器上的環境變數、~/.aws 金鑰、git 憑證,就被打包送出去了。
那筆「錯誤」不是你的程式產生的。是攻擊者灌進來的。而那段「修復步驟」,是寫給你的代理人看的指令。這就是資安團隊 Tenet Security 在 2026 年 6 月公開、命名為 Agentjacking 的攻擊——而它要的不是某個工具的零號漏洞,是 AI 編碼代理人(AI coding agent)一個更底層的習慣:它分不出「自己讀到的資料」和「要它執行的指令」。
一個公開 DSN,怎麼變成代理人手上的指令?
攻擊鏈只有四步,每一步用的都是現成、合規的東西。
第一步,拿到目標的 Sentry DSN。 DSN 是 Sentry 的 write-only 憑證,設計上就是公開的——它本來就嵌在網站前端的 JavaScript 裡,好讓瀏覽器能回報錯誤。攻擊者用原始碼檢視、Censys 搜尋或 GitHub 程式碼搜尋就能撈到,不需要任何額外認證。
第二步,POST 一筆假錯誤。 拿著這個 DSN,攻擊者對 Sentry 的 ingest endpoint 送出一筆自製的錯誤事件。重點在 payload:它用 markdown 注入在錯誤訊息與 context 欄位裡,做成一個假的「## Resolution」區塊,視覺與語法都和 Sentry 自己產生的診斷模板「難以區分」。區塊裡是一條 npm 指令——Tenet 在驗證時用的是自己控制的套件 npx @tenet-controlled-validation-package --diagnose。
第三步,等開發者叫代理人去看。 這一步不需要攻擊者做什麼。開發者哪天請代理人透過 MCP(Model Context Protocol)去查 Sentry 的 issue,Sentry 的 MCP server 就把那筆被注入的事件,連同一般事件一起回傳給代理人。按 Cloud Security Alliance 的研究筆記,MCP 的回應「沒有任何訊號指出這段內容是攻擊者寫的、而不是應用程式自己跑出來的」。
第四步,代理人照做。 代理人把假的 Resolution 當成權威診斷指引,以開發者本人的系統權限執行那條 npx——未經使用者再次確認。套件一裝,攻擊者的程式就在你的機器上跑起來了。
為什麼三個主流代理人都中招?
這不是某一家的事。Tenet 把三個目前最多人用的編碼代理人都測了,行為一致:
| 代理人 | 測試環境 | 結果 |
|---|---|---|
| Claude Code(v2-1-161) | macOS,環境內有 AWS 金鑰 | 執行注入指令 |
| Cursor | 全新安裝、預設值;含 Warp 終端機整合 | 執行注入指令 |
| OpenAI Codex | 沙箱化 CI/CD(CircleCI、EC2 容器) | 執行注入指令 |
三者都把注入的 markdown 讀成「正常的診斷步驟」,沒有把它和真實的應用程式錯誤分開,也沒有在執行那條 npm 指令前要求授權。值得注意的是最後一行:連跑在 CI/CD 沙箱裡的代理人也中——沙箱限制了網路與環境,卻沒有改變「代理人信任 MCP 回來的資料」這件事。
Tenet 用一句話定性整個攻擊面:「AI 編碼代理人分不出它讀到的資料,和要它行動的指令。」只要外部資料能流進代理人,那就是一條可以下指令的路。
規模有多大、能拿走什麼?
以下數字由 Tenet 自報,受測對象為事先同意(consenting)的組織,第三方尚未獨立復現:
- 2,388 個組織被被動偵察找到帶有可注入的 DSN;
- 在對 100+ consenting 組織的受控測試中,完整代理人執行的成功率 85%;
- 實證 100+ 次真實的代理人執行;
- 暴露橫跨 6 大洲,其中 71 個目標落在 Tranco 前 100 萬網站。
代理人權限所及的東西就是能被拿走的東西:環境變數、~/.aws/config 裡的 AWS 金鑰、GitHub OAuth token、SSH agent socket 與 git 憑證、Kubernetes token、雲端基礎設施憑證、私有 repo 的 URL。Tenet 記錄攻擊在 macOS、Windows、WSL、CI/CD、EC2、GCP、受網路限制的沙箱,甚至內網 VPN 環境都成功過。
破口在哪一環:資料、信任邊界,還是權限?
把 Agentjacking 讀成「Sentry 出包」會錯估範圍。Sentry 的 DSN 公開是設計如此,而它對這次揭露的回應是:在來源端「technically not defensible at the platform level」——平台端防不了——並把根因責任指向模型廠商,只針對 PoC 用到的特定 payload 字串上線了一個全域內容過濾。研究者形容這是治標。
讀成「某個 AI 工具不安全」也偏掉,因為三個主流代理人的行為一致。CSA 的筆記把根因定在 MCP 的信任邊界上:「代理人信任用來取資料的任何服務,那個服務就成了下指令的潛在管道」,而且這個注入面「延伸到 MCP server 暴露的每一個資料源——包括那些接受組織信任邊界以外輸入的資料源」。
換句話說,破口是三件事疊出來的:代理人分不出資料與指令、MCP 把外部來源包裝成可信輸入、代理人又握有系統權限。Sentry 只是第一個被示範的入口——任何讓外部輸入流進 MCP 的資料源,理論上都在同一條線上。責任的拉扯也卡在這裡:Sentry 說該由廠商在代理人端把關,而代理人的預設行為是直接執行。
你的工作流,哪一環在這條攻擊線上?
Tenet 揭露的時間軸是這樣:2026-06-03 通報 Sentry,6 月中公開,Cloud Security Alliance 在 6 月 12 日發出研究筆記。截至報導,各模型廠商是否會調整代理人「讀到外部資料就直接照做」的預設行為,沒有看到明確的公開聲明。
對台灣大量用「Claude Code/Cursor/Codex + Sentry + MCP」這套組合的軟體與新創團隊來說,Agentjacking 不是別人的故事:把 DSN 嵌進前端、把 MCP 接到外部資料源,都是現在的常態,而攻擊本身不分地理。
這篇能放到你面前的,是那張信任邊界的地圖:資料從哪個外部來源流進代理人、代理人在哪一環把它當成了指令、它手上有多大權限能把後果放大。Agentjacking 證明的不是哪個工具壞了,而是「資料即指令」這道邊界,在代理人握有系統權限之後,第一次被大規模實證地走完了一遍。
資料來源:Tenet Security(Agentjacking: Coding Agents with Fake Sentry Errors)、Cloud Security Alliance(CSA Research Note,2026-06-12)、The Hacker News、Infosecurity Magazine。
LEARN
想系統性學會,不只看這一則?
用 Claude Code 完成真正的工作
讓 Claude Code 在你的專案裡完成一個真實任務,而且控得住權限、驗得了 diff、管得住成本。
從第 0 課開始 →SOURCES
- A Agentjacking: Coding Agents with Fake Sentry Errors
- A CSA Research Note: Agentjacking (MCP / Sentry Injection)
- B Agentjacking Attack Tricks AI Coding Agents Into Running Malicious Code
- B New "Agentjacking" Attacks Could Hijack AI Coding Agents
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- 工作現場
- Key claims
-
- 攻擊入口是公開的 Sentry DSN——一個 write-only 憑證,本就嵌在前端 JavaScript,可由原始碼檢視、Censys 或 GitHub 程式碼搜尋找到,攻擊者無需額外認證即可對目標的 Sentry ingest endpoint POST 一筆錯誤事件。
- 惡意指令偽裝成 Sentry 的修復步驟:用 markdown 注入在錯誤訊息與 context 欄位,做成與 Sentry 真實診斷模板視覺與語法難以區分的假 Resolution 區塊,內含一條 npx 指令。
- Tenet 實測 Claude Code(v2-1-161)、Cursor、OpenAI Codex 三個主流代理人都會把注入的 markdown 當成正常診斷步驟、未經使用者授權就執行該指令,連 CircleCI、EC2 沙箱 CI/CD 也中招。
- 規模為研究團隊自報、受測對象為 consenting 組織:被動偵察找到 2,388 個帶可注入 DSN 的組織,受控測試 85% 完整代理人執行成功率,實證 100+ 次代理人執行,暴露橫跨 6 大洲。
- Tenet 於 2026-06-03 向 Sentry 揭露、6 月中公開;Sentry 承認問題但稱在來源端 technically not defensible at the platform level,把根因責任指向模型廠商,僅針對 PoC payload 字串上線全域內容過濾。
- Entities
- Tenet Security · Cloud Security Alliance · Sentry · Model Context Protocol · Claude Code · Cursor · OpenAI Codex
- Taiwan relevance
- high
- Confidence
- medium
- Last updated
- 2026-06-23
- Canonical URL
- https://signals.tw/articles/agentjacking-sentry-mcp-coding-agents/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
矽基前沿 · 工作現場線(編輯:廖玄同),《一封假的 Sentry bug 回報,就能讓 Claude Code、Cursor、Codex 替攻擊者跑指令》,矽基前沿 [Si]gnals,2026-06-23。https://signals.tw/articles/agentjacking-sentry-mcp-coding-agents/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.