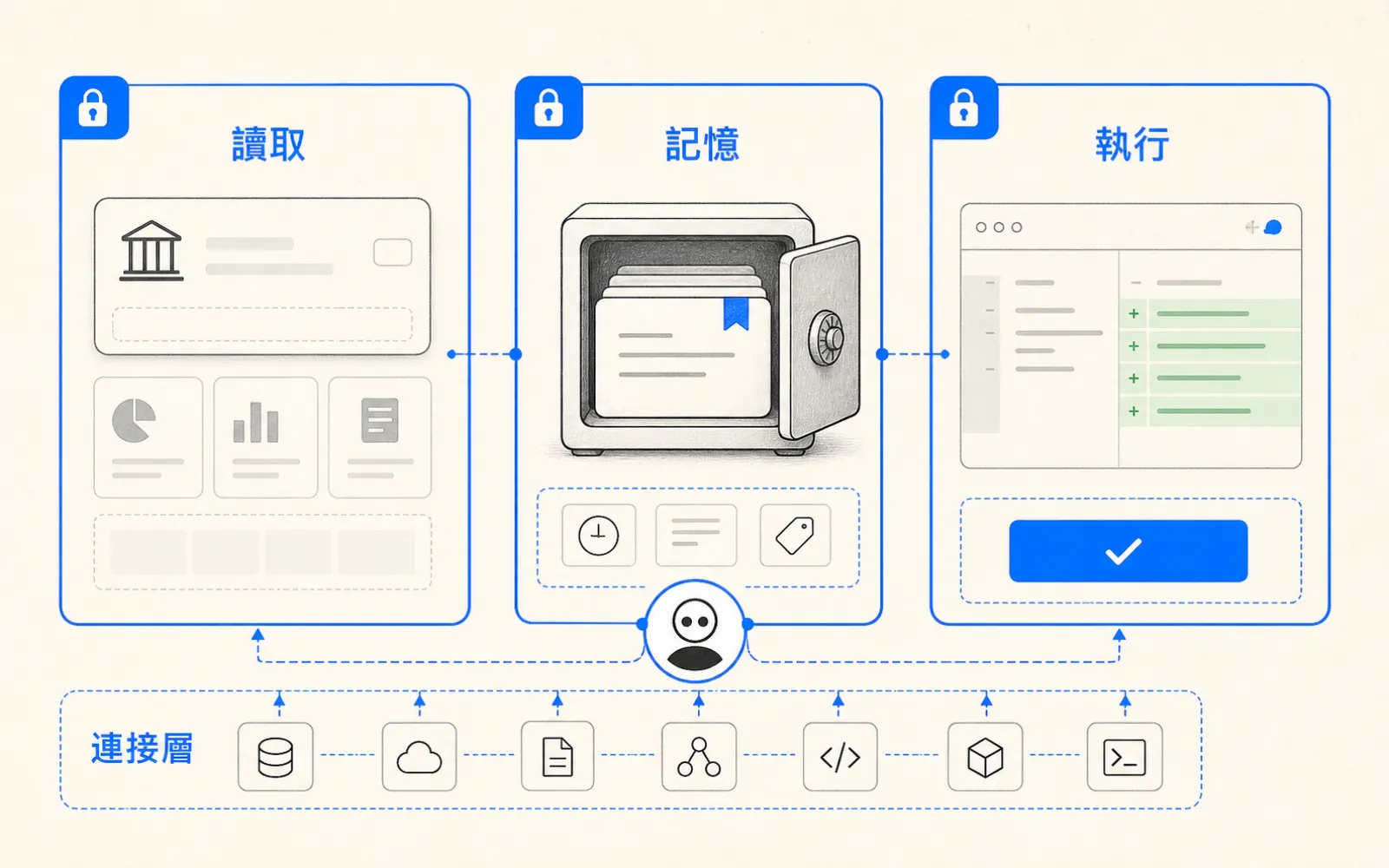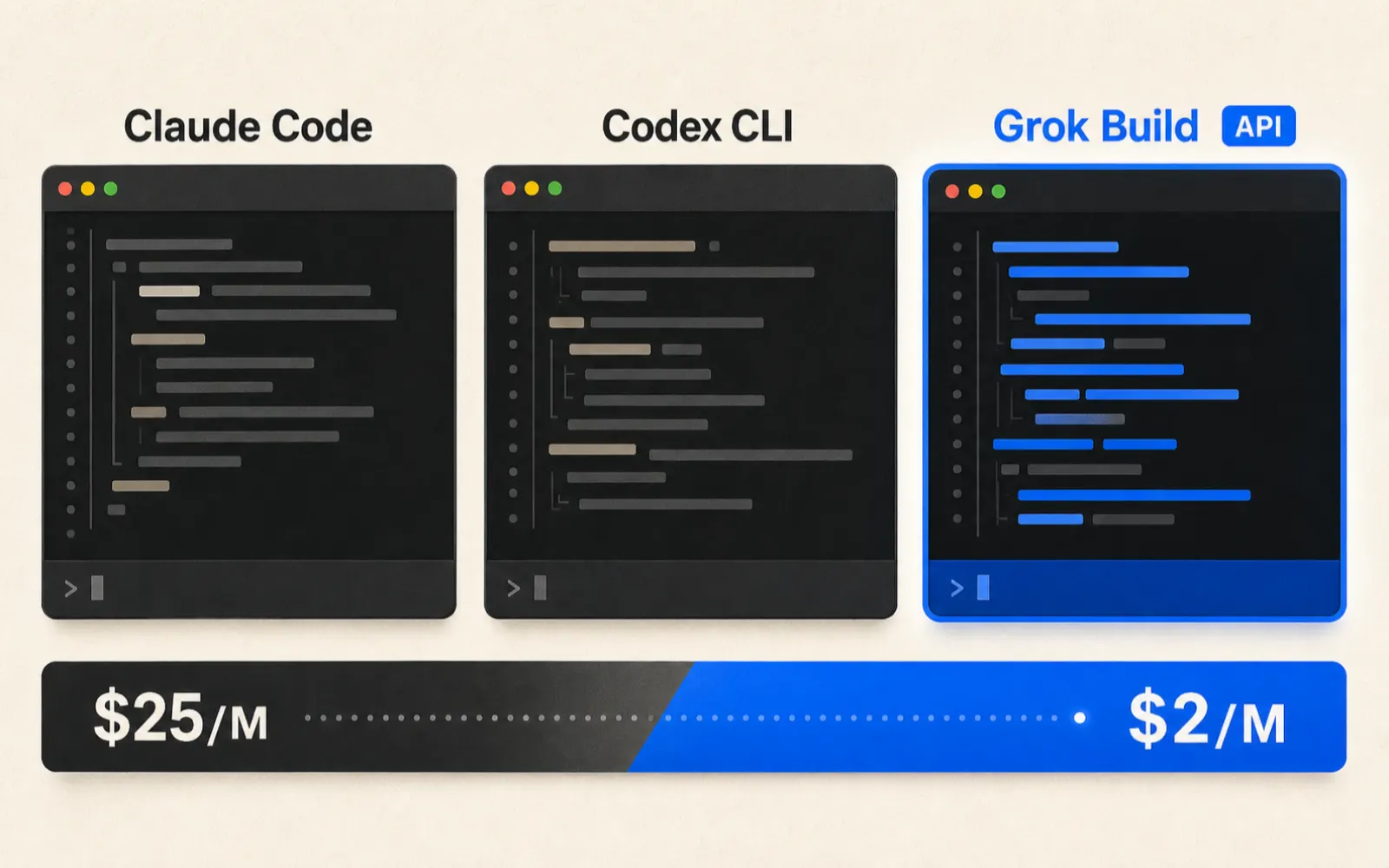
Grok Build 開進 API,AI coding agent 三強路線開始分叉
xAI 昨天把 grok-build-0.1 開放進 API 公測:每百萬 output token 2 美元,比 Claude Opus 4.7 便宜 12 倍。這不是第三名加入競賽——是定價和入口設計的路線正式出現分歧。
重點一:xAI 在 2026 年 5 月 28 日把
grok-build-0.1開放進 API 公測,定價 $1/M input、$2/M output,支援 prompt caching(最高 90% 折扣)。這是繼 5 月 25 日擴開訂閱入口後,Grok Build 的第二波開放動作。重點二:
grok-build-0.1的 SWE-Bench Verified 分數為 70.8%(xAI 自測),比 Claude Opus 4.7 約低 15 個百分點;但 output 成本是 $2/M vs $25/M,差距 12.5 倍。重點三:API 入口的意義不只是「多一個工具選項」——它讓任何有 xAI API key 的開發者可以把 Grok 的 coding model 整進自己的工具鏈,不需要訂閱 xAI 的 CLI 服務。
同一個月,三個 coding agent 都在搶你的 terminal。
Anthropic 的 Claude Code 在 5 月 19 日推出 MCP tunnels 研究預覽版,讓代理人能透過隧道連接本機開發環境。OpenAI 的 Codex CLI 在 5 月 14 日把批准介面搬上 iOS,工程師可以在手機上審核代理人動作。xAI 的 Grok Build 在昨天(5 月 28 日)做了另一件事:把 coding model 開進 API 公測,每百萬 output token 2 美元。
三家的動作方向不一樣。讀懂這個分叉,比知道誰「最強」更重要。
Grok Build 是什麼?CLI 和 API 的差別,昨天開放了什麼
Grok Build 從 5 月 14 日開始對 SuperGrok Heavy 訂戶(每月 $300)進入早期測試。它是一個 terminal coding agent:你在本機 terminal 用自然語言下指令,代理人生成計畫、執行指令、寫程式、跑測試。程式碼在你的機器上執行,xAI 表示工作階段期間不傳送 codebase 到伺服器(廠商主張,未經第三方驗證)。
5 月 25 日,Grok Build 擴展到所有 SuperGrok 和 X Premium+ 訂戶,搭配 $99/月的促銷方案(前 6 個月)。這兩週 Grok Build 都是訂閱制工具:你用訂閱換工具使用權,沒有 API 入口。
昨天(5 月 28 日)的更新改變了這件事。
xAI 把 grok-build-0.1 開放進 xAI API 公測。這代表任何有 xAI API key 的開發者,現在可以直接呼叫這個 coding model,不需要訂閱 Grok Build CLI,也不需要使用 xAI 的 terminal 介面。模型的規格:256K tokens 上下文窗口、100+ tokens/秒吞吐、支援 MCP 與 ACP(Agent Client Protocol)。
白話講:從訂閱制 terminal 工具,變成開放 API 的 coding model 基礎設施。
三種入口,三種適用場景:從訂閱 CLI 到開放 API,誰服務誰
三家 coding agent 的入口模型不同,而入口決定了誰能用、怎麼整進工具鏈。
| 工具 | 訂閱入口 | API 入口 | 適合場景 |
|---|---|---|---|
| Claude Code | Pro $20/月、Team $25/人·月、Enterprise | API:$5/M input、$25/M output | 個人開發、企業工具鏈整合、自建 coding agent |
| Codex CLI | ChatGPT Plus/Pro 訂閱 | OpenAI API(GPT-5.5 系列定價) | 個人開發、IDE 整合、行動裝置批准 |
| Grok Build | SuperGrok $99/月(促銷)、X Premium+ | API:$1/M input、$2/M output(新) | 個人開發、API 工具鏈整合(新) |
訂閱入口服務的是「直接使用工具的開發者」。API 入口服務的是兩類人:直接用工具的開發者,以及在自己的系統或產品裡整合 coding model 的開發者。
Grok Build 在昨天開了 API 入口,代表第二類場景現在多了一個每百萬 output token 2 美元的選項。
成本矩陣:70.8% 配 $2/M,哪些任務算法不同
這是這篇最需要算清楚的部分。
grok-build-0.1 在 SWE-Bench Verified 上的分數是 70.8%(xAI 自有測試環境)。Claude Opus 4.7 的分數約在 85% 左右(依 Anthropic 公告的「coding benchmark 提升 13%」推算),高了約 15 個百分點。光看 benchmark,Grok Build 是老三。
但 output 成本:$2/M tokens vs Claude Opus 4.7 的 $25/M tokens。
Grok Build 的 SWE-Bench 分數比 Claude Opus 4.7 低 15 個百分點,但 output 成本便宜 12 倍。如果你選的不是「最聰明的工具」,而是「最適合批次任務的工具」,計算式從頭到尾都不同。
加上 prompt caching 最高 90% 折扣(反覆使用相同 codebase 背景脈絡時),Grok Build 的有效 input 成本可以更低。
換句話說,$2/M 的存在改變了哪些任務分類的經濟計算:
- 需要高準確率的關鍵路徑任務(核心業務邏輯修改、複雜重構、有嚴格測試需求的程式):15 個百分點的差距是真實風險,選 Claude Opus 4.7 或 GPT-5.5 系列更合理。
- 可容許 70% 準確率的批次任務(樣板程式碼生成、大規模 lint 修正、重複性 API wrapper、CI 腳本):12 倍的成本差是真實節省,Grok Build 的 API 計算式就不同了。
Anthropic 自己的 Claude Code 使用成本估算是每位開發者每個 active day 平均 13 美元、每月 150 到 250 美元。這個數字在大量 agentic 任務下可以更高。若工程主管有機會把部分批次任務路由到 $2/M 的 output,節省空間是量級差異,不是百分比差距。
架構路線:plan mode、subagent、行動批准——三家設計哲學
三家工具的架構路線,反映了對「代理人應該怎麼被監督」的不同理解。
Grok Build 的方式:
plan mode 是 Grok Build 最有特色的設計。代理人先生成一個任務節點圖,包含每個子任務的狀態,顯示在專用 TUI(terminal UI)裡,讓你在任何程式碼被修改之前先看到完整計畫。確認後,代理人啟動最多 8 個並行 subagent,各自在隔離的 Git worktree 上工作,同時修改不同部分的 codebase 不會互相衝突。
Claude Code 的方式:
單代理人主線加 MCP 整合。May 19 的 MCP tunnels 研究預覽讓代理人能透過隧道連接本機環境;Anthropic Managed Agents 已進公測,提供 self-hosted sandbox 和企業稽核日誌。Claude Code 的設計哲學傾向把安全隔離和企業治理放在架構核心。
Codex CLI 的方式:
/goal 指令產生線性文字計畫(非 Grok Build 的節點圖),行動批准可以透過 iOS/Android App 遠端操作——工程師不在電腦旁也能審核代理人動作。Chrome extension 讓 DevTools 也進入代理人可見範圍。Codex 的設計傾向讓批准動作可以發生在任何裝置上。
三條路線代表三種哲學:執行前完整計畫圖(Grok Build)/ 企業安全框架優先(Claude Code)/ 批准動作隨時隨地(Codex CLI)。
選工具前的 4 個問題:你的任務分類決定了計算式
在比較三家工具前,先回答這 4 個問題。
1. 你是在「用工具」,還是在「建工具」?
直接在 terminal 用 AI 助手寫程式,訂閱制入口就夠。如果你在建內部工具、白牌產品,或設計一套 AI coding pipeline,你需要 API 入口。API 入口現在有 Grok Build $1/$2/M 這個選項。
2. 你的任務有 benchmark 底線嗎?
關鍵路徑任務需要 85% 準確率的,70.8% 不夠。批次、樣板、重複性任務可容納更高錯誤率的,$2/M 的成本差距開始有意義。同一個工程團隊,不同任務可能需要不同答案。
3. 你有反覆使用相同 codebase 背景脈絡的需求嗎?
Prompt caching 讓 Grok Build 在重複讀相同 codebase context 時,input 成本最高折 90%。大型 codebase 的批次任務場景,這個折扣很有意義。
4. 你需要什麼層次的監督機制?
Grok Build 的節點圖計畫 → 選 Grok Build。企業合規隔離與稽核日誌 → 選 Claude Code。遠端行動裝置批准 → 選 Codex CLI。
Grok Build API 的出現,沒有讓三強競賽的結果立刻改變。Claude Code 和 Codex CLI 在 benchmark 分數和生態完整度上的優勢仍在。
但 $2/M output token 的存在,改變了一件事:成本分類的粒度。 過去,coding agent 的成本預算只有一種計算單位——某家廠商的訂閱費加 API token 費用。現在工程主管手上多了一個選項:把部分任務路由到更便宜的 coding model。差距不是 10%,是 12 倍。這個差距夠大,大到值得工程主管重新看一遍自己的任務分類,問:哪些任務,我不需要最聰明的那個?
資料來源:xAI 官方公告 Grok Build 0.1 API、xAI 官方公告 Grok Build CLI(x.ai/news/grok-build-0-1、x.ai/news/grok-build-cli)、Anthropic Claude Opus 4.7 公告(anthropic.com)、SWE-Bench 分數資料(benchlm.ai)、DevOps.com、CIO Dive、ChatForest 評測。
SOURCES
- A Grok Build 0.1 on API
- A Introducing Grok Build
- A Grok Build Changelog
- B xAI Enters the Coding Agent Race With Grok Build
- B xAI joins crowded coding agent race with Grok Build
- B Grok Build CLI Review
- B Grok Build 0.1 Benchmarks
- A Introducing Claude Opus 4.7
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- AI 戰爭
- Key claims
-
- xAI 在 2026 年 5 月 28 日把 grok-build-0.1 開放進 API 公測,定價為 $1/M input、$2/M output,支援 prompt caching(最高 90% 折扣)。
- grok-build-0.1 的 SWE-Bench Verified 分數為 70.8%(xAI 自測),比 Claude Opus 4.7 約低 15 個百分點,但 output 成本是 $2/M vs $25/M,相差 12.5 倍。
- Grok Build API 入口讓開發者可以把 grok-build-0.1 整進自己的工具鏈,不需要訂閱 Grok Build CLI。
- 三家 coding agent 現在有三種不同的入口模型:Claude Code(訂閱+API)、Codex CLI(訂閱+OpenAI API)、Grok Build(訂閱+xAI API)。
- 選工具前的關鍵問題不是「誰最強」,而是「哪些任務需要 85% 準確率,哪些 70% 就夠」。
- Entities
- xAI · Grok Build · grok-build-0.1 · Anthropic · Claude Code · Claude Opus 4.7 · OpenAI · Codex CLI
- Taiwan relevance
- medium
- Confidence
- medium
- Last updated
- 2026-06-10
- Canonical URL
- https://signals.tw/articles/xai-grok-build-api-coding-race/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
謝皓文(編輯:廖玄同),《Grok Build 開進 API,AI coding agent 三強路線開始分叉》,矽基前沿 [Si]gnals,2026-06-10。https://signals.tw/articles/xai-grok-build-api-coding-race/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.