OpenAI 想把資安 AI 先交給防守者,問題是誰算可信?
同一套 AI 能幫防守者補洞,也能幫攻擊者找洞。OpenAI 的答案不是全開放,而是用 Trusted Access 把能力分層交給受驗證的防守者。
同一套 AI 可以幫防守者找漏洞、寫修補建議、加速事件回應;也可以幫攻擊者更快偵察目標、生成釣魚內容、降低入門門檻。
OpenAI 4 月 29 日發布 Cybersecurity in the Intelligence Age 行動計畫,真正值得看的不是它列了五大支柱,而是它替這個矛盾提出一個分發答案:不要把前沿資安能力只鎖在少數人手裡,也不要無限制開放,而是用 Trusted Access for Cyber 把能力分層交給受驗證的防守者。
這套邏輯可以濃縮成一句話:高能力資安 AI 不再只靠模型拒絕來管理,而是開始靠「誰能用、怎麼用、誰看得到、誰能撤權」來管理。
為什麼不是把能力全部鎖起來?
OpenAI 在行動計畫裡把這個取捨稱為 controlled acceleration。它的前提是,攻擊者不會等平台慢慢設計完美制度;現有模型已經能支援部分資安流程,未來能力也會更快擴散。
因此,OpenAI 反對兩種極端。
第一種是把前沿資安能力限制在極少數核准夥伴。這看似保守,但會讓政府、金融、關鍵基礎設施、開源維護者和一般企業防守者拿不到足夠工具。
第二種是把能力一次放給所有人。這會放大雙用風險,因為「請幫我找這段程式碼的漏洞」可能是負責任修補,也可能是未授權攻擊的前置工作。
OpenAI 的答案是受控加速:讓可信防守者更快取得能力,同時保留防護、監控、干預與撤權工具。這不是單一產品功能,而是一套 access-control 制度。
Trusted Access 管的是能力分發
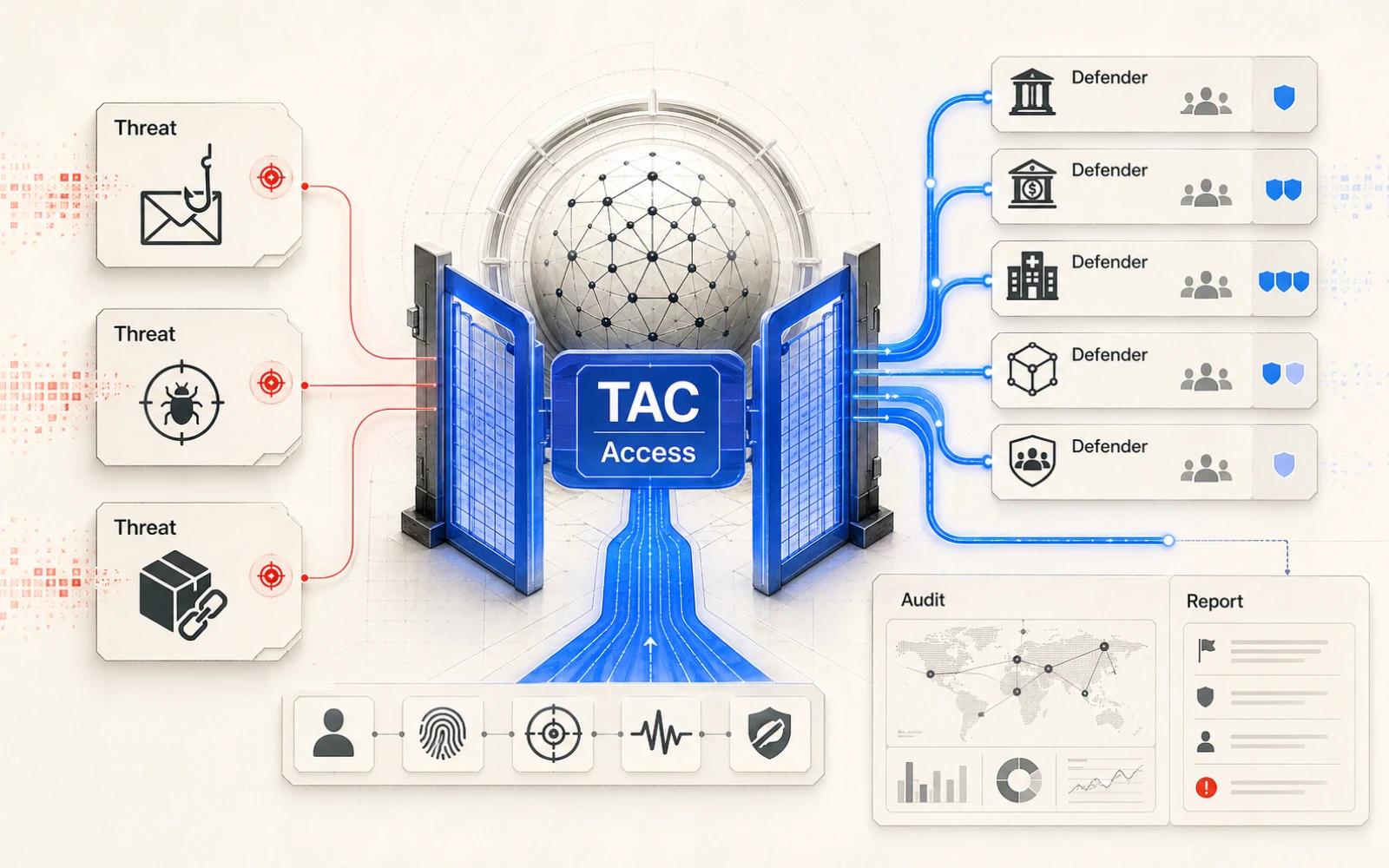
Trusted Access for Cyber,簡稱 TAC,是 OpenAI 用來分發更高 cyber capabilities 的機制。
它的核心不是「這個模型比較懂資安」,而是「能力越強,使用者要提供越多信任證據」。OpenAI 在 PDF 裡說,TAC 會依 trust、mission need 和 defensive impact 分層;越 powerful 或越 permissive 的能力,越需要更強的 vetting、security commitments、monitoring 和 use-case requirements。
這代表資安模型的採購問題開始變得很像雲端權限治理。
誰能申請?是個人研究者、企業 team、MSSP、金融機構、政府單位,還是開源維護者?
可以做什麼?是檢查自己的程式碼、做授權滲透測試、分析惡意程式,還是協助下游客戶修補?
平台能看到什麼?是即時 classifier、離線 monitoring、威脅情資 enrichment,還是只看最小必要訊號?
如果風險升高,OpenAI 能做什麼?它列出的工具包括提高帳號摩擦、降低 quota、要求重新驗證、降級 access tier,甚至移除 access。
這些問題比「模型評測分數多高」更接近企業實際會遇到的風險。
五大支柱裡,真正的機制是哪幾個?
OpenAI 的五大支柱包括民主化 cyber defense、政府與產業協調、強化前沿資安能力的安全、保留部署可見性與控制,以及讓一般使用者保護自己。
如果只看標題,這會像一份政策口號。但把五點拆開,真正的機制有三個。
第一是分層 access。OpenAI 計畫把 TAC 擴到各層級政府防守者、能保護大量 downstream users 的產業角色、金融等重點部門、以及小型醫院、學校、水務、公用事業和地方機構。資源少的組織不一定直接操作前沿模型,可能透過 MSSP、產業組織、security vendors 或 CISA-supported programs 取得防守能力。
第二是跨機構協調。OpenAI 說 access 本身不夠,政府、產業和 AI lab 需要更快共享威脅行為者、基礎設施、工具、手法、目標模式和繞過 safeguards 的技術。這是它希望把個別 access decisions 變成防守生態系的地方。
第三是部署後控制。OpenAI 不把安全只放在上線前,而是強調上線後控制手段:如果濫用或威脅上升,設定、限制、quota、驗證和 access tier 都要能調整。靜態 safeguard 在這裡不夠用。
企業買方該問的不是「有沒有 AI 資安工具」
對企業、政府和資安團隊來說,OpenAI 這份計畫的實用價值不是照抄五大支柱,而是把採購問題問得更細。
第一,供應商如何驗證使用者身份和用途?
如果一個工具提供更 permissive 的漏洞分析、逆向工程或攻擊路徑推理,買方要知道它是用組織身份、個人身份、專案用途還是安全責任來決定 access。
第二,監控和隱私如何同時成立?
OpenAI 說高風險 deployment 需要 monitoring、abuse reporting 和 threat-intelligence enrichment。買方要追問哪些資料會被看見、保存多久、是否會進入供應商威脅分析流程,以及員工和客戶資料如何被隔離。
第三,責任怎麼分配?
如果企業透過資安平台、MSSP 或雲端供應商間接使用高能力 cyber AI,事故發生時責任在模型供應商、工具供應商、服務商,還是使用企業?這會影響合約、稽核和保險。
第四,access 能不能被撤回?
強能力模型不只需要上線審查,也需要下線機制。買方應要求清楚的降級、停用、告警、申訴與事件回報流程,否則「可信使用者」會變成一次性認證,而不是持續治理。
這也是 OpenAI 對 AI lab 角色的重新包裝
OpenAI 最近同時推進 FedRAMP Moderate、TAC 擴大、GPT-5.4-Cyber 和資安生態合作。把這些放在一起看,它正在把自己從模型供應商包裝成資安防守基礎設施的一部分。
這裡有好處,也有風險。
好處是,大型 AI lab 確實有能力看到跨客戶、跨平台的濫用模式,也能把更強模型、程式碼代理人和修補工具整合到防守流程。對小型組織來說,如果只靠內部資安人力,很難追上攻擊自動化。
風險是,這套制度把很多判斷交給模型供應商:誰算 trusted defender、哪些用例值得更高權限、哪些訊號足以降級或撤權、哪些濫用需要回報政府或產業夥伴。這些決策不是純技術問題,也會影響市場入口和客戶權力。
所以這篇不該讀成 OpenAI 終於找到資安 AI 的答案。更準確地說,它公開了一套 OpenAI 希望市場接受的資安 AI 分發規則。
前沿模型越能做資安工作,採購問題就越不像「買一個工具」,越像「接入一套受控能力」。企業現在該問的不是模型有多強,而是強能力被放在哪個 access tier、誰能審核、誰能看到濫用、誰能在風險升高時撤權。
SOURCES
- A Cybersecurity in the Intelligence Age
- A Cybersecurity in the Intelligence Age: An Action Plan for Democratizing AI-Powered Cyber Defense
- A Introducing Trusted Access for Cyber
- A Trusted access for the next era of cyber defense
- A OpenAI available at FedRAMP Moderate
- B OpenAI opens powerful cyber tools to verified users
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- AI 戰爭
- Key claims
-
- OpenAI 在 2026 年 4 月 29 日發布 Cybersecurity in the Intelligence Age article and action plan,主張用五大支柱推進 AI-powered cyber defense。
- OpenAI 的核心取捨是 controlled acceleration:更快把高能力模型交給受信任防守者,同時保留 safeguards、monitoring 和 intervention tools。
- Trusted Access for Cyber 將更強或更 permissive 的 cyber capabilities 放進分層 access,依 trust、mission need 和 defensive impact 提高審核與監控要求。
- 企業和政府買方採購 AI 資安工具時,應同時檢查身份驗證、用途邊界、稽核、濫用回報、資料可見性與撤權機制。
- Entities
- OpenAI · Trusted Access for Cyber · TAC · GPT-5.4-Cyber · ChatGPT · Codex Security · FedRAMP · CISA · Frontier Model Forum
- Taiwan relevance
- medium
- Confidence
- high
- Last updated
- 2026-04-29
- Canonical URL
- https://signals.tw/articles/openai-cyber-defense-action-plan/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
謝皓文(編輯:廖玄同),《OpenAI 想把資安 AI 先交給防守者,問題是誰算可信?》,矽基前沿 [Si]gnals,2026-04-30。https://signals.tw/articles/openai-cyber-defense-action-plan/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.