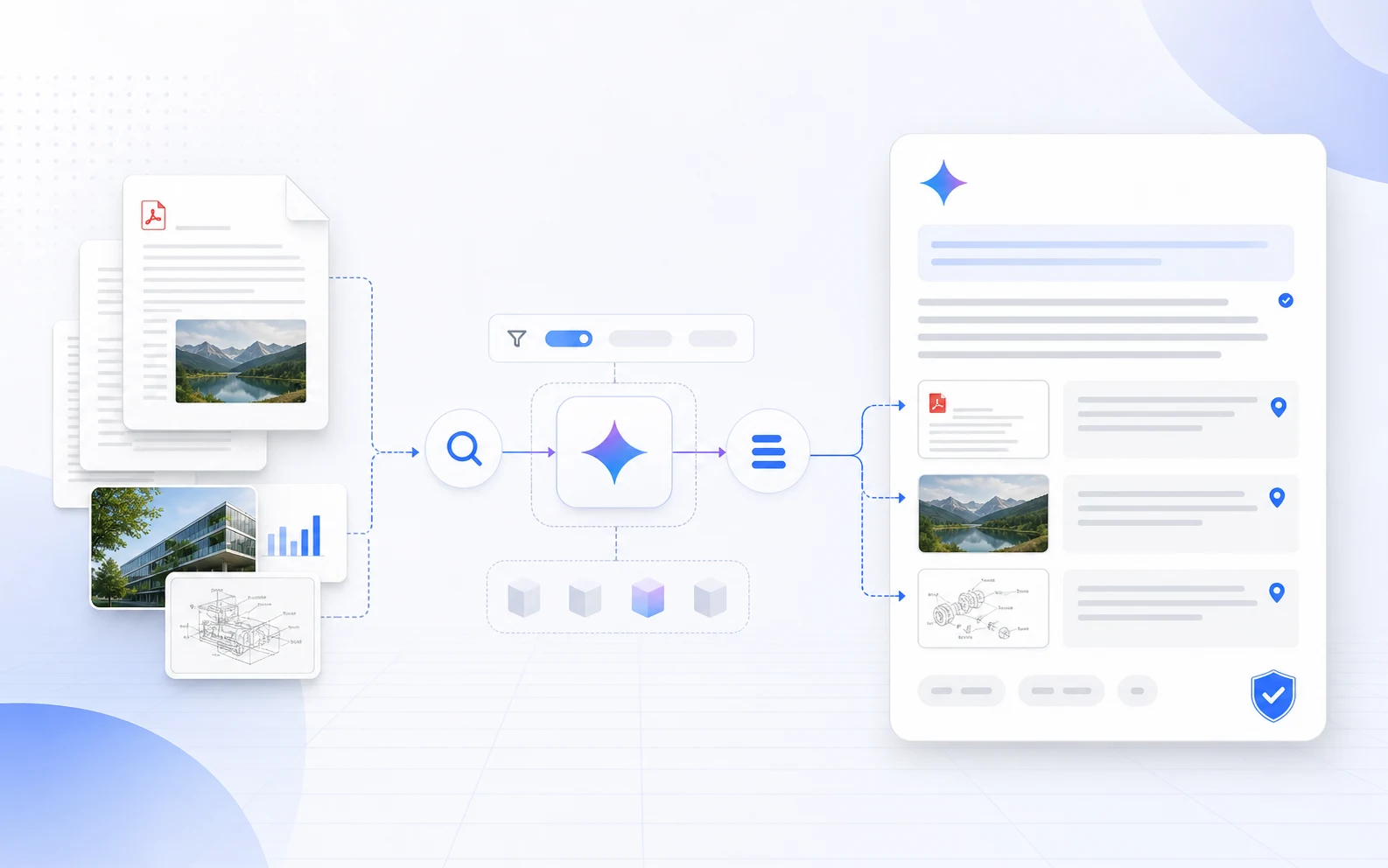
Gemini File Search 會看圖片和頁碼,RAG 終於能回頭查證
Google 讓 File Search 支援多模態檢索、metadata filter 和頁碼引用。對開發者來說,重點轉向答案背後的查證路徑:它到底看了什麼,能不能查回去。
Google 在 2026 年 5 月 5 日更新 Gemini API File Search,加入多模態支援、自訂 metadata filter 與頁碼引用。本文拆解開發者該如何評估 RAG 答案的查證路徑。
一家產品團隊問內部助理:「去年 onboarding 流程改版,哪一張流程圖提到審核步驟?」
資料不在同一個地方。有 PDF 規格書、Figma 匯出的截圖、客服 SOP,也有幾張舊流程圖。傳統做法是把文件丟進 RAG,讓模型回一段看起來合理的答案。麻煩在後面:它到底看了哪份文件?哪一頁?哪張圖?查詢時有沒有混到別的部門資料?
Google 5 月 5 日更新 Gemini API File Search,值得看的正是這個追問。這次更新把焦點從「把資料丟進去」移到幾個更接近實務的查證點:多模態索引、自訂 metadata filter、頁碼引用,以及圖片片段的 media ID。
如果你正在做內部知識助理,這些細節比「支援 RAG」四個字更值得看。
RAG 不能只讀文字,也要找得到圖
Google 的公告說,File Search 現在支援多模態資料與自訂 metadata,並引入 page-level citations。官方文件補上了實作邊界:File Search 會匯入、切塊、建立 embedding、索引資料,再把檢索結果作為模型回答的上下文。
多模態部分的關鍵設定是 embedding model。文件寫得很直接:如果要用 Multimodal File Search,建立 FileSearchStore 時要把 embedding model 設成 models/gemini-embedding-2,才能處理文字和圖片。圖片目前支援 PNG、JPEG,解析度上限是 4K x 4K;音訊與影片還不在支援範圍內。
這讓 RAG 更接近公司資料的真實樣子。很多內部知識並不住在純文字裡,而是藏在產品截圖、架構圖、流程圖、表單掃描檔、研究圖表和簡報頁面。以前這些東西常常只能靠檔名或人工標籤被搜尋;多模態 retrieval 的價值,是讓「圖裡的資訊」也能被問到。
但這也提高了檢查門檻。當一個助理說它找到某張圖時,團隊不能只看答案漂亮不漂亮,還要能回到那張圖,確認它是不是拿對資料。
Metadata filter 先把資料範圍切對
File Search 的另一個更新是自訂 metadata。文件示範的形式很樸素:你可以在匯入檔案時加上 key-value,例如 author 或 year,查詢時再用 metadata_filter 限定範圍。
這看起來像小功能,實際上碰到企業 RAG 很常見的痛點。很多錯誤回答來自錯誤資料集合裡的看似相關片段,並非模型能力本身突然失常。
例如同一家公司可能有:
- 法務版合約範本與業務版銷售簡報。
- 台灣區價格表與美國區價格表。
- 已發布產品文件與開發中草稿。
- 2024 年舊 SOP 與 2026 年新版流程。
如果沒有查詢範圍,模型可能把過期、跨區、跨部門的片段混在一起。metadata filter 的作用,是在模型回答前先縮小「可以被拿來回答的資料」。
它不是資安系統,也不會自動解決權限控管。比較準確的定位是一個檢索前置閘門:先把資料切到正確集合,再讓模型找片段。
頁碼和圖片 ID 讓答案可以回查
Google 文件說,File Search 的回應可能包含 grounding_metadata。如果檢索的是有頁面的文件,例如 PDF,回應可能包含 page_number;如果引用圖片片段,metadata 可能包含 media_id,讓應用程式可以下載或顯示被引用的圖片 chunk。
這是這次更新最適合被產品團隊放進測試清單的地方。
| 問題 | 沒有 citation 時 | 有頁碼 / media ID 時 |
|---|---|---|
| 答案來自哪裡 | 只能相信模型摘要 | 可以回到文件頁面或圖片片段 |
| 錯誤怎麼查 | 從整份資料庫人工翻 | 從引用片段開始查 |
| 權限怎麼檢查 | 很難看出混到哪些資料 | 可以檢查被引用資料是否屬於允許範圍 |
| 使用者怎麼建立信任 | 看語氣和格式 | 看來源、頁碼、圖片 chunk |
要小心的是,citation 只能說模型使用或引用了某個片段,不能當成答案正確證明。片段本身可能過期,模型可能誤讀,問題也可能需要多個片段才能回答。
所以測試時不要停在「有沒有 citation」,要把問題推到四個檢查點:
- citation 是否指向足夠精確的位置。
- 被引用內容是否真的支持答案。
- 如果答案錯了,團隊能否從 citation 找到錯誤來源。
- 產品介面能不能讓使用者看見這個回查路徑。
Managed File Search 適合誰,自建又留給誰
Gemini API File Search 的價值,是讓開發者少處理一大段 retrieval infrastructure。官方文件說,File Search 會處理匯入、切塊、embedding、索引與查詢;File Search store 裡的資料會保存到手動刪除或模型淘汰,透過 Files API 上傳的原始檔則會在 48 小時後刪除。
這樣的抽象適合幾種情境:
| 需求 | File Search 可能夠用 | 可能需要自建或混合 |
|---|---|---|
| 快速建立內部文件助理 | 是 | 如果權限模型很複雜 |
| 搜尋 PDF、圖片、圖表 | 是,取決於格式 | 如果要支援音訊、影片或特殊解析 |
| 需要頁碼與圖片回查 | 是 | 如果要自訂 citation UI 和 ranking |
| 嚴格控制排序與召回 | 未必 | 通常需要自建 retrieval layer |
| 跨系統權限與稽核 | 需要額外設計 | 常見於企業自建平台 |
因此,這次更新的判斷不該停在「Google 也有 RAG」。更實際的問法是:這個工作流需要你控制每一個 retrieval primitive,還是先需要一個可回查、可快速上線的 managed layer?
如果你只是做一個部門文件助理,File Search 的頁碼、metadata 和圖片 citation 可能已經能大幅降低第一版風險。若你要處理細緻權限、客製 ranking、跨資料源 lineage,或必須完整記錄每一次召回,那 managed layer 只能是其中一層。
開發者該帶走的測試清單
測 Gemini API File Search,不要只看 demo 答案像不像專家。拿一組真實但低風險的資料,最好同時包含 PDF、圖片和版本差異,然後檢查五件事:
- 查詢能不能用 metadata 限定範圍。
- 回答能不能回到頁碼或圖片片段。
- 引用片段是否真的支持答案。
- 資料保存、刪除和 store 管理是否符合團隊流程。
- 當 citation 沒出現或不夠精準時,產品要怎麼提示使用者。
RAG 的競爭會越來越落在資料路徑:誰能把答案背後的查詢範圍、頁碼和圖片片段交代清楚。Gemini API File Search 這次補上的,正是這條路徑的一部分。它距離完整的企業檢索治理方案還有一段距離,但已經把一個關鍵問題擺到產品介面上:回答之前找了什麼,回答之後怎麼查。
SOURCES
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- 工作現場
- Key claims
-
- Google 在 2026 年 5 月 5 日宣布 Gemini API File Search 新增多模態支援、自訂 metadata 與頁碼引用。
- Gemini API 文件顯示,多模態 File Search 需要使用 `models/gemini-embedding-2`,目前圖片支援 PNG、JPEG,音訊與影片尚未支援。
- File Search 的 citation metadata 可以包含 PDF 頁碼或圖片 media ID,但 citation 只改善查證路徑,不等於答案必然正確。
- Entities
- Google · Gemini API · Gemini Embedding 2 · File Search
- Taiwan relevance
- medium
- Confidence
- high
- Last updated
- 2026-05-09
- Canonical URL
- https://signals.tw/articles/gemini-api-file-search-multimodal-rag/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
林子睿(編輯:廖玄同),《Gemini File Search 會看圖片和頁碼,RAG 終於能回頭查證》,矽基前沿 [Si]gnals,2026-05-09。https://signals.tw/articles/gemini-api-file-search-multimodal-rag/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.