用 AI 代理人客製模型前,先看 SageMaker 留下哪些工作產物
AWS 把模型客製化包進 IDE 裡的代理人流程。速度只是入口;更值得檢查的是每一步有沒有可審、可改、可重跑的產物。
AWS 在 2026 年 5 月 4 日推出 SageMaker AI model customization agent experience。本文用測試流程拆解它如何處理使用情境、資料、fine-tuning、評估與部署。
開發者在 IDE 裡丟出一句話:「幫我把客服分類資料拿來客製一個模型。」
這句話以前通常只是一段需求的開始。接下來還有目標定義、資料格式、基礎模型選擇、微調方法、評估方式、部署路徑、權限、成本和回滾。AWS 5 月 4 日推出的 SageMaker AI model customization agent experience,想把這些步驟放進 AI 代理人(AI agent)能陪你走完的開發流程裡。
這件事值得寫,原因不在於「模型微調突然變簡單」。如果團隊這樣讀,風險會更高。更有價值的讀法是:AWS 正在把模型客製化拆成一串代理人可讀的 skills,讓每一步產生可以被人審、被修改、被重跑的工作產物。
你要看的不只是一句完成回報,還要看代理人留下什麼。
第一個檢查:使用情境有沒有變成規格
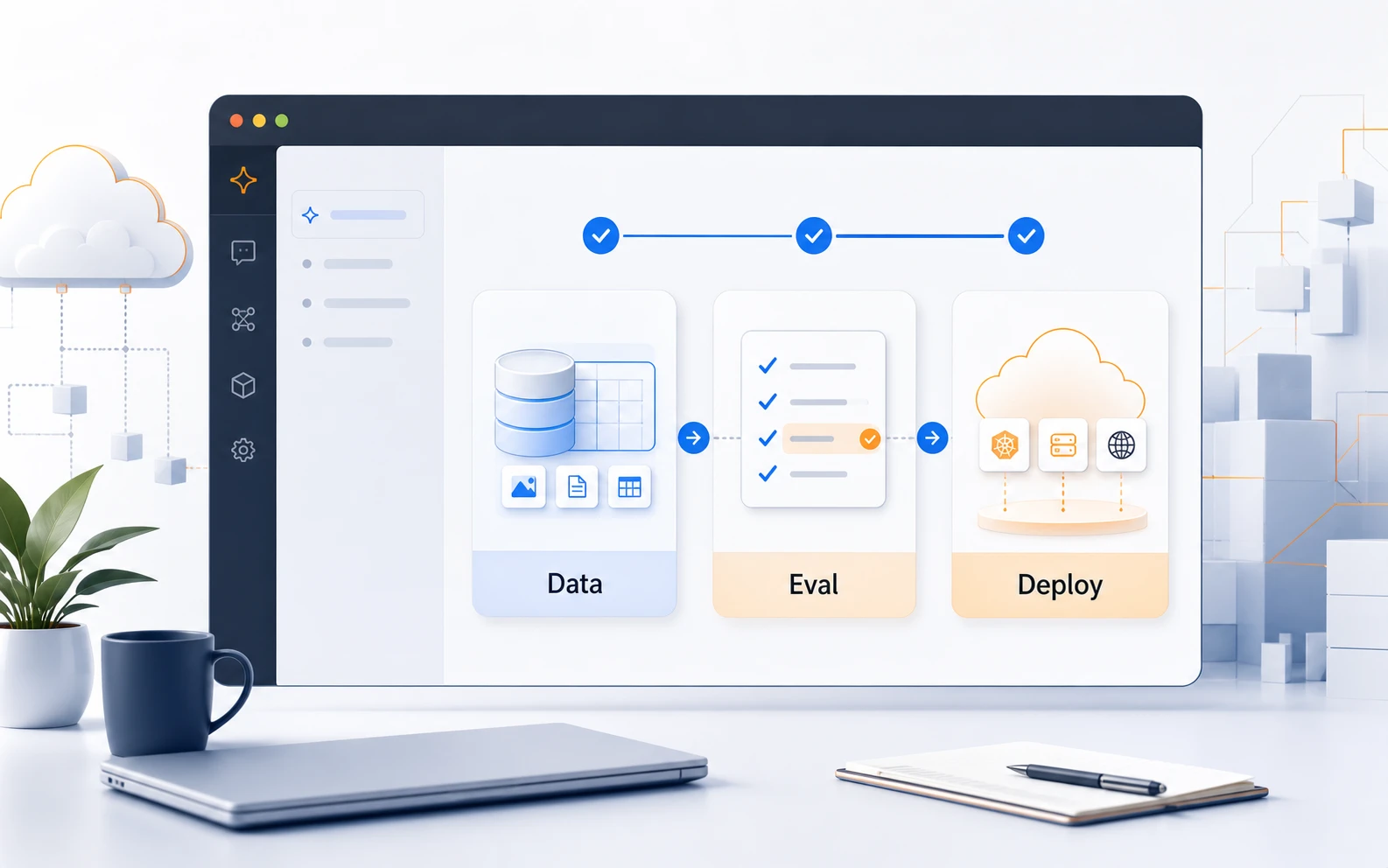
AWS 的官方更新說,這個 agent experience 會從 use case goals、success criteria、資料準備、模型選擇、實驗設定、評估和部署一路處理。awslabs 的 sagemaker-ai plugin README 則把流程拆得更細:planning、use-case-specification、dataset-evaluation、dataset-transformation、finetuning-setup、finetuning、model-evaluation、model-deployment。
這份清單是文章的第一個具體物件。
如果你要測它,起點不要放在「請幫我 fine-tune」。比較好的測法是給一個小型、低風險的任務,例如客服訊息分類、內部 FAQ 風格調整、或產品描述語氣調整,然後看代理人能不能釐清三件事:
- 這個模型要改善哪個使用場景。
- 什麼輸出算成功。
- 哪些資料不能進訓練或評估流程。
沒有這三件事,後面的資料轉換和評估都只是形式。
第二個檢查:資料和 notebook 能不能被人接手
AWS 的文件把 model customization assets 分成資料集、evaluator、reward function 或 reward prompt 等資產。這代表代理人不只是在聊天裡給建議,它必須把材料整理成可操作的格式。
awslabs plugin 裡最重要的一句話,是它會產生 executable Jupyter notebooks,讓使用者 review、edit、run cell by cell。
這是客製模型流程的關鍵檢查點。團隊不應該只看最後有沒有模型 endpoint,而要打開 notebook 看:
- 資料格式轉換是否清楚標出來源和輸出。
- 訓練集、驗證集和評估集是否分開。
- 使用的微調方法是 SFT、DPO、RLVR 還是 RLAIF。
- 超參數和模型選擇是否寫在可追蹤的位置。
- 每個步驟是否能在沒有聊天上下文的情況下重跑。
如果 notebook 只是包裝過的黑盒,那代理人只是把複雜性移到更難查的地方。如果 notebook 可讀、可改、可重跑,它才可能成為團隊流程的一部分。
第三個檢查:評估會不會只剩一句好不好
AWS 說這套 experience 支援 LLM-as-a-judge metrics,也支援部署到 Amazon Bedrock 或 SageMaker AI endpoints。這聽起來完整,但評估最容易被寫成漂亮流程圖。
實際檢查時,至少要看四個欄位:
| 檢查項目 | 你要看到什麼 |
|---|---|
| 評估資料 | 與訓練資料分離,能代表真實任務 |
| 評估標準 | 不只是一句「品質更好」,而是明確任務標準 |
| 評審方式 | LLM-as-a-judge 的 prompt、模型和限制可見 |
| 失敗樣本 | 有地方記錄錯誤案例,而非只保留平均分 |
這裡也要記得 source boundary。AWS 說流程可把傳統上耗時數月的工作壓到 days or hours,這是官方產品敘述。文章不能把它寫成所有專案的實證結果。資料品質、標註、法務、資安和成本審核,仍然可能吃掉最多時間。
第四個檢查:部署前,權限和區域要先露出來
這次更新列出支援區域,包括 us-east-1、eu-west-1、us-west-2 和 ap-northeast-1。對台灣團隊來說,東京區域出現在清單裡,降低了測試門檻,但不等於資料和合規判斷可以略過。
plugin README 的限制更務實。它要求 AWS credentials、SageMaker 權限、Bedrock 評估或部署時的補充權限,也提到某些 bucket 命名和 Lambda 權限 caveat。Kiro 使用者還要注意,文件說 SageMaker model customization skills 在 Kiro 的 “vibe” mode 會正確觸發,但 “spec” mode 不一定穩定。
這些細節比發布文更有用。因為它們告訴你,代理人進入 ML 流程後,第一個現實障礙常常落在環境:權限、區域、模式、bucket、Lambda 和部署路徑。
這適合怎麼試
這篇文章的建議很窄:先把它當流程鷹架測,不要當自動 fine-tune 按鈕。
一個合理測試可以這樣設計:
- 選一個低風險 use case,例如公開資料的分類任務。
- 要求代理人產出 use case specification。
- 檢查 dataset transformation notebook。
- 讓它提出 SFT / DPO / RLVR / RLAIF 的選擇理由。
- 看 evaluation notebook 是否能被另一位工程師獨立重跑。
- 在部署前停下來檢查 IAM、region、Bedrock evaluation 成本和資料邊界。
如果這六步都能留下清楚工作產物,SageMaker 的新代理人流程就有測試價值。如果中間任何一步只剩聊天摘要,那團隊得到的可能只是更快的錯覺。
開發者該帶走的判斷很簡單:不要問代理人能不能幫你客製模型,先看它能不能把客製模型這件事拆成可審查、可重跑、可交接的工作。這才是 SageMaker 這次更新最值得檢查的地方。
SOURCES
- A Amazon SageMaker AI launches AI agent experience for model customization
- A Customizing models with Amazon SageMaker AI
- A awslabs agent-plugins sagemaker-ai plugin
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- 工作現場
- Key claims
-
- AWS 在 2026 年 5 月 4 日宣布 SageMaker AI model customization agent experience。
- 該流程以 SageMaker AI skills 支援 use case 定義、資料轉換、fine-tuning、LLM-as-a-judge 評估,以及部署到 Bedrock 或 SageMaker endpoints。
- awslabs 的 sagemaker-ai plugin 文件顯示,工作流會產生可審閱、可編輯、可逐格執行的 Jupyter notebooks。
- Entities
- AWS · Amazon SageMaker AI · Amazon Bedrock · Kiro · Claude Code · Cursor
- Taiwan relevance
- medium
- Confidence
- high
- Last updated
- 2026-05-07
- Canonical URL
- https://signals.tw/articles/aws-sagemaker-model-customization-agent/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
林子睿(編輯:廖玄同),《用 AI 代理人客製模型前,先看 SageMaker 留下哪些工作產物》,矽基前沿 [Si]gnals,2026-05-08。https://signals.tw/articles/aws-sagemaker-model-customization-agent/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.