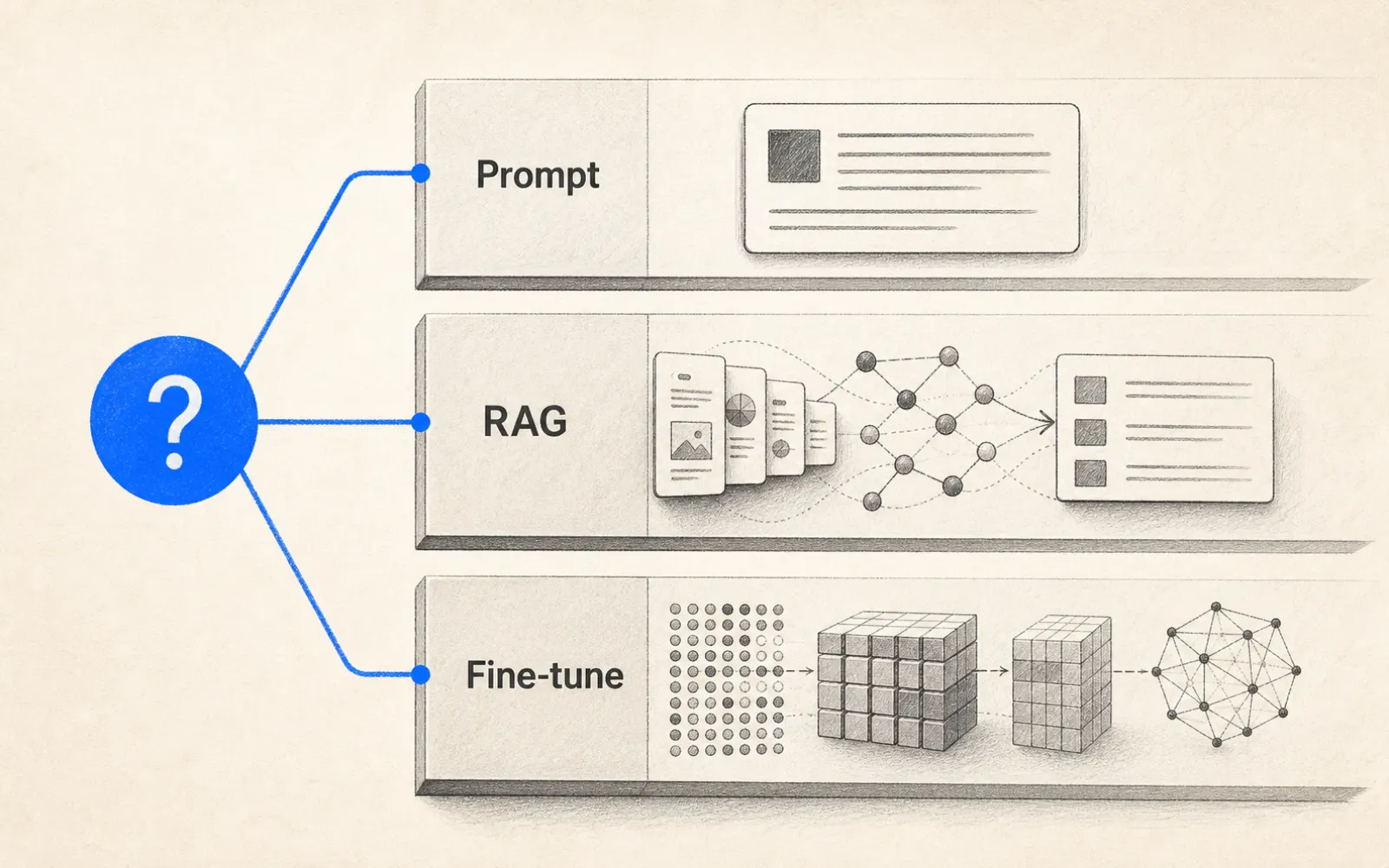
Fine-tune、RAG、還是 Prompt?AI 模型適配三條路徑的選擇框架
Fine-tune 改訓練、RAG 改上下文、Prompt 改指令。三條路徑住在堆疊的不同層,選錯層的代價,往往比選錯模型更貴
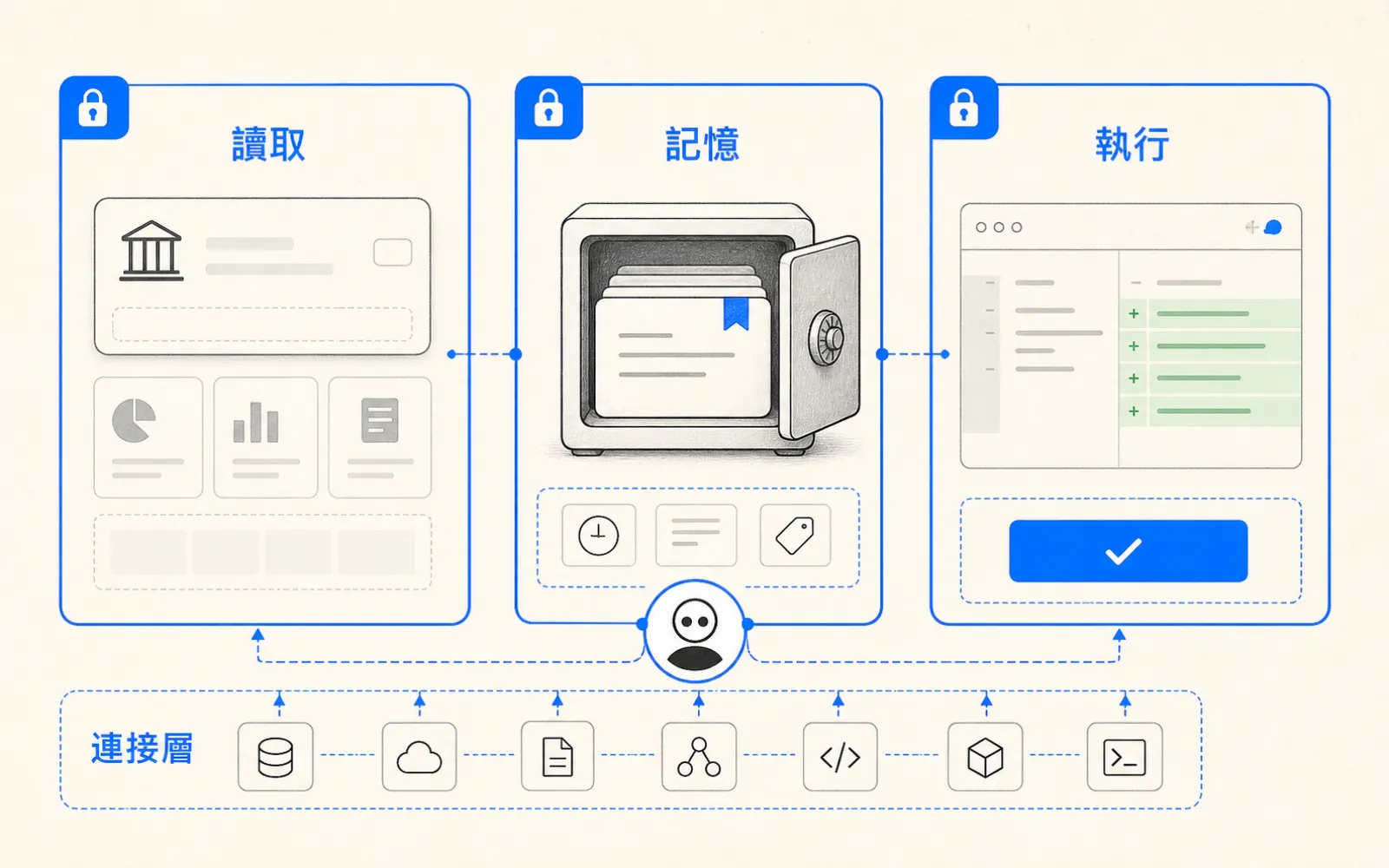
重點一:Fine-tune 修改模型「已學到的知識與行為」;RAG 修改模型「每次推論時看到的資料」;Prompt engineering 修改「你怎麼指定任務」。三件事住在 AI 堆疊的不同層,解決不同性質的問題。
重點二:最貴的浪費發生在第二輪迭代:把 fine-tune 用在 RAG 就能解決的知識問題,或用 RAG 補 prompt engineering 就能修好的格式問題——症狀看起來一樣,根因卻住在不同層。
重點三:導入前先問五個問題:這是知識邊界還是行為習慣問題?資料更新頻率如何?Prompt engineering 真的解不了嗎?你有能力維護訓練資料集嗎?需要輸出可追溯嗎?
同一個月,三個台灣 AI 開發團隊遇上同樣的困境:接上 LLM 的客服機器人,答案不夠準確。三個團隊做了三個不同的決定,走進三條完全不同的路。
第一個團隊決定 fine-tune。工程師花了三週整理訓練資料、兩週跑實驗,付出數百到數千美元的訓練費用。模型的回答更準了——但三個月後,公司更新了退款政策,模型的答案又開始錯。
第二個團隊導入 RAG(Retrieval-Augmented Generation,檢索增強生成)。他們把公司的常見問答文件和政策說明放進向量資料庫,讓模型每次回答前先查詢最相關的段落。三天做出概念驗證,政策更新時只需換文件,模型不用重跑。
第三個團隊用一個下午改了 system prompt,加入清楚的角色定義、拒絕範圍、輸出格式要求,以及五個 few-shot 範例,輸出的格式與語氣穩定了下來。
三個團隊都說自己「選對了」。
這三個場景是台灣導入現場的合成縮影,但三條路徑的成本與邊界是可查的——它們寫在 OpenAI 與 Anthropic 的官方文件、以及 RAG 的原始論文裡。問題是:在你的情況下,哪條才是對的?
三條路徑住在哪一層:Fine-tune 改訓練、RAG 改上下文、Prompt 改指令
要回答這個問題,先要搞清楚這三條路徑分別在哪裡動手。
Fine-tuning 是在訓練層操作。你提供一組輸入/輸出對,讓模型在這批資料上繼續訓練,更新模型內部的權重。結果是一個「被重新塑形」的模型變體:它的預設行為、輸出風格、對特定術語的熟悉度,都和原始模型不同。
RAG 是在上下文層操作。模型本身不變——但每次推論時,系統先去向量資料庫搜索最相關的文件片段,把它們塞進 prompt,讓模型「在看到這些資料的情況下」回答。Lewis et al. 2020 年的原始論文把這個架構稱為「parametric + non-parametric 記憶的混合」:模型的參數記憶不變,但每次推論都能查閱動態的外部知識庫。
Prompt engineering 是在指令層操作。同樣的模型、同樣的知識,靠寫更好的 system prompt、更精確的 few-shot 範例、更清楚的格式要求,改變推論時的輸出。
白話講:Fine-tune 改變模型學到了什麼;RAG 改變模型看到了什麼;Prompt engineering 改變你要求模型做什麼。三件事住在堆疊的不同層,選錯層不會讓模型更聰明,只會讓你的 sprint 更長。
三層是獨立的,可以混用,但每層解決的問題性質不同——混用前必須先知道你的問題住在哪一層。
Fine-tune:什麼時候改寫模型比補資料更划算?
Fine-tuning 同時存在「被過度使用」和「被過度低估」的情況。
OpenAI 官方文件把 fine-tuning 的推薦使用場景列得很清楚:
- 風格與格式的一致性:輸出必須嚴格符合特定格式(JSON schema、固定長度、特殊語氣),且 few-shot 範例放在 prompt 裡還不夠
- 壓縮 prompt 長度:把反覆出現的長篇指令「燒進」模型,節省每次推論的 token 成本
- 領域術語的自然化:讓模型把業界縮寫、內部命名當作自然語言使用,而不是每次都需要在 prompt 裡解釋
- 高精度邊緣情況:某些特定輸入的處理方式,用 few-shot 範例範圍不夠,需要大量標注資料訓練
同樣是 OpenAI 文件,裡面也說了一句很多人跳過的話:在嘗試 fine-tuning 之前,應該先嘗試 prompt engineering 和 few-shot prompting,因為 prompt 的迭代速度遠快於訓練週期,也不需要準備標注資料。
Fine-tuning 不解決的問題:
| 問題類型 | 為什麼 fine-tune 無效 |
|---|---|
| 模型不知道最新的業務規則 | Fine-tune 是靜態的,知識截止日後的事實不會自動更新 |
| 每次查詢需要不同的動態資料 | 模型權重不能每次查詢都重訓 |
| 頻繁更新的政策/文件 | 每次更新都需要重新標注、重新訓練 |
Fine-tuning 的隱性成本被長期低估。訓練費用本身只是一部分:標注資料的人工成本、建立評估 pipeline 的工程時間、以及最容易被忽略的——每次業務規則改變時的重訓成本。
如果你的應用場景是「公司政策、產品資訊、FAQ 類的問答」,fine-tuning 幾乎一定不是最好的路徑。
RAG:它解決的是「記憶邊界」,不是「能力邊界」
RAG 是目前企業 AI 導入最常被誤用的技術之一。誤用方向有兩種:一種是「哪裡不對就加 RAG」,另一種是「RAG 能解決模型的所有局限」。
RAG 解決的是這個:模型的訓練資料有截止日,且不包含你的私有知識。RAG 讓模型在推論時能「讀到」它訓練時沒有看過的文件——但模型處理這些文件的能力,仍然取決於它的訓練。
換句話說:RAG 解決的是知識邊界(我知道嗎?),不是能力邊界(我能理解嗎?)。
RAG 不解決的問題:
- 輸出格式不一致:模型知道答案但輸出格式亂——這是指令層的問題,改 prompt 就好
- 語氣/角色扮演的穩定性:模型有時候忘記自己是誰——這也是指令層問題
- 領域術語的理解:如果某個術語在訓練時從來沒見過,把包含這個術語的文件塞進 RAG 也未必有用——模型看到但讀不懂
RAG 的實際成本結構也值得拆清楚。初始建置(chunking、embedding、向量資料庫設置)小專案 1–3 天可以完成。但每次查詢會有額外的 token 成本——上下文通常膨脹到原本的 2–5 倍,意味著每次 API 費用增加。大規模部署時,這個成本累積得很快。
Prompt Engineering:被系統性低估的第一步
台灣 AI 開發者在第二輪迭代最常出現的討論是「我們要不要 fine-tune 模型?」答案幾乎永遠是:「先試試把 prompt 寫好。」
Anthropic 在 Building Effective Agents 指引裡建議:從最簡單的架構開始,只有在更簡單的解法無法滿足需求時,才加入更複雜的層。這個原則直接對應到適配路徑的選擇順序:先試 prompt engineering,不夠才加 RAG,再不夠才試 fine-tune。
Prompt engineering 能做的事,常常超過開發者的預期:
- 明確的輸出格式指令(JSON schema、固定欄位、長度限制)可以大幅壓低格式錯誤率
- Chain-of-Thought(CoT)指令可以讓模型在複雜推理任務上把推理步驟攤開,準確率明顯改善
- Few-shot 範例(3–5 個)可以讓模型學會特定任務的輸出模式
- 拒絕邊界的明確化(「如果不確定,說不確定,不要猜」)可以大幅減少幻覺
Prompt engineering 的限制確實存在:context window 有上限,無法注入海量文件;大量並行推論時,複雜的 system prompt 有時會不穩定;某些高度專業的輸出格式,few-shot 範例放不下。這些才是升級到 RAG 或 fine-tune 的合理觸發點。
成本怎麼比:Prompt 幾乎免費、RAG 墊高推論費、Fine-tune 吃掉維運
| 維度 | Prompt Engineering | RAG | Fine-tuning |
|---|---|---|---|
| 初始時間 | 幾小時到幾天 | 1–3 天(概念驗證),1–3 週(生產就緒) | 2–6 週(資料準備 + 訓練 + 評估) |
| 初始費用 | 幾乎零 | 低–中(向量 DB + embedding) | 中–高(訓練費 + 標注成本) |
| 每次推論費用 | 基準值 | 基準值 × 2–5 | 基準值(但用的是 fine-tuned 版本) |
| 知識更新成本 | 改 prompt 即可 | 更新文件庫即可 | 需要重新標注 + 重訓 |
| 維運複雜度 | 最低 | 中(需要 chunking/retrieval pipeline) | 最高(需要持續維護訓練資料集) |
| 輸出可追溯性 | 低 | 高(可回溯到來源文件) | 低 |
白話講:Prompt engineering 是永遠應該先試的那條。RAG 是知識密集型應用的主力方案。Fine-tuning 是當行為一致性的要求超過 prompt 可以穩定控制的範圍時的選項。
三種常見失敗模式:每一種都是把問題放錯了層
失敗模式 1:把 fine-tune 做了 RAG 就能解決的問題
症狀:模型不知道公司的最新退款政策或產品資訊,工程師開始整理訓練資料。
根因:這是「知識邊界」問題,不是「行為習慣」問題。業務資料會持續更新,fine-tune 是靜態解法。
正確路徑:把政策文件和產品說明放進 RAG 文件庫,讓模型每次查詢時動態撈取。
失敗模式 2:用 RAG 補了 prompt engineering 就能修好的格式問題
症狀:模型回答有時中英夾雜、格式不統一,團隊建了複雜的 RAG 系統,把格式範例做成文件注入上下文。
根因:這是「指令層」問題——清楚的輸出格式要求 + 幾個 few-shot 範例就夠了。
正確路徑:先修 system prompt,加上明確的輸出格式指令和 3–5 個範例,不需要 RAG。
失敗模式 3:Fine-tune 後沒有維運計畫
症狀:模型 fine-tune 後效果很好,三個月後業務規則改了,模型答案開始偏。
根因:Fine-tuning 是靜態的,業務規則動態變化的情況下,維運成本被嚴重低估。每次重訓都要重新準備資料、跑評估、部署新版本。
正確路徑:評估業務規則的更新頻率。如果每個月都在變,RAG 通常是更合適的主力方案。
導入前的判斷清單:先回答這五個問題再動手
判斷適配路徑不需要猜——先回答這五個問題:
1. 問題是「知識邊界」還是「行為習慣」?
模型不知道某個事實 → 知識邊界 → RAG(或 fine-tune 含事實,但更新頻繁時 RAG 優先)
模型知道但格式/語氣/風格不對 → 行為習慣 → Prompt engineering 或 fine-tune
2. 資料更新頻率如何?
每週或每月更新 → RAG(只需更新文件庫)
穩定的知識體系,基本不變 → 可以考慮 fine-tune,但先算重訓成本
3. Prompt engineering 真的解不了嗎?
先花一到兩天把 prompt 做到極致:角色定義清楚、輸出格式明確、加上三到五個 few-shot 範例。
如果效果已經達到八成,繼續把 prompt 做深;真的碰到天花板,再升級到 RAG 或 fine-tune。
4. 你有能力維護訓練資料集嗎?
Fine-tuning 需要持續維護高品質的標注資料。如果你的團隊沒有標注能力或資料 pipeline,RAG 通常是更可維運的選擇。
5. 需要輸出可追溯嗎?
需要引用來源、每個答案可以回溯到具體文件 → RAG
不需要來源追溯、要求行為一致且風格穩定 → Fine-tune 或 prompt engineering
把這五個問題的答案列出來,正確的路徑通常自己就會浮現。台灣最常見的三個場景——客服、內部知識管理、文件摘要——答案幾乎都是:先把 prompt engineering 做到極致,再決定要不要加 RAG。Fine-tuning 是例外,不是預設選項。
資料來源:OpenAI Fine-tuning 官方文件、Anthropic Prompt Engineering 官方文件、Lewis et al. (2020) Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (arXiv:2005.11401)、Anthropic Building Effective Agents 指引、OpenAI Embeddings 官方文件。
SOURCES
- A OpenAI Fine-tuning Guide
- A Anthropic Prompt Engineering Overview
- A Lewis et al. (2020) — Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- B Anthropic — Building Effective Agents
- A OpenAI Embeddings Guide
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- 工作現場
- Key claims
-
- Fine-tune 修改模型的訓練權重(行為層);RAG 在推論時注入外部知識(上下文層);Prompt engineering 修改任務指令(指令層)。三者住在堆疊的不同層,解決不同性質的問題,互不替代。
- OpenAI 官方文件明確建議,在嘗試 fine-tuning 之前,應先嘗試 prompt engineering 與 few-shot prompting,因為 prompt 迭代速度遠快於訓練週期。
- RAG 解決的是「知識邊界」問題:讓模型在推論時看到它訓練資料沒有涵蓋的資訊;fine-tune 解決的是「行為習慣」問題:讓模型的輸出風格、格式、術語更一致。
- Fine-tuning 的隱性成本超過訓練費用本身:需要持續維護訓練資料集,每次業務規則改變都需要重新訓練;而 RAG 只需更新文件庫,不需重訓模型。
- Anthropic 的 Building Effective Agents 指引建議從最簡單的架構開始(prompt + tools),只有在 prompt engineering 無法滿足需求時才加入 retrieval 或微調層。
- Entities
- OpenAI · Anthropic · RAG · fine-tuning · prompt engineering · LLM
- Taiwan relevance
- medium
- Confidence
- high
- Last updated
- 2026-06-10
- Canonical URL
- https://signals.tw/articles/ai-model-adaptation-three-paths/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
林子睿(編輯:廖玄同),《Fine-tune、RAG、還是 Prompt?AI 模型適配三條路徑的選擇框架》,矽基前沿 [Si]gnals,2026-06-10。https://signals.tw/articles/ai-model-adaptation-three-paths/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.