Google 用 Gemini 讀新聞,補出 260 萬筆洪災紀錄:AI 預警卡在資料底稿
Groundsource 把全球新聞報導轉成城市閃洪資料集,讓 Flood Hub 有更完整的歷史基準,也讓 AI 預警的資料缺口變得可見。
要預測城市閃洪,麻煩常常不在雨雲本身,而在過去的水到底怎麼淹。
哪個路口淹過、哪一天淹、報導寫的是街區還是整座城市,這些資訊如果沒有被整理成機器能讀的資料,AI 預警就少了一塊地基。
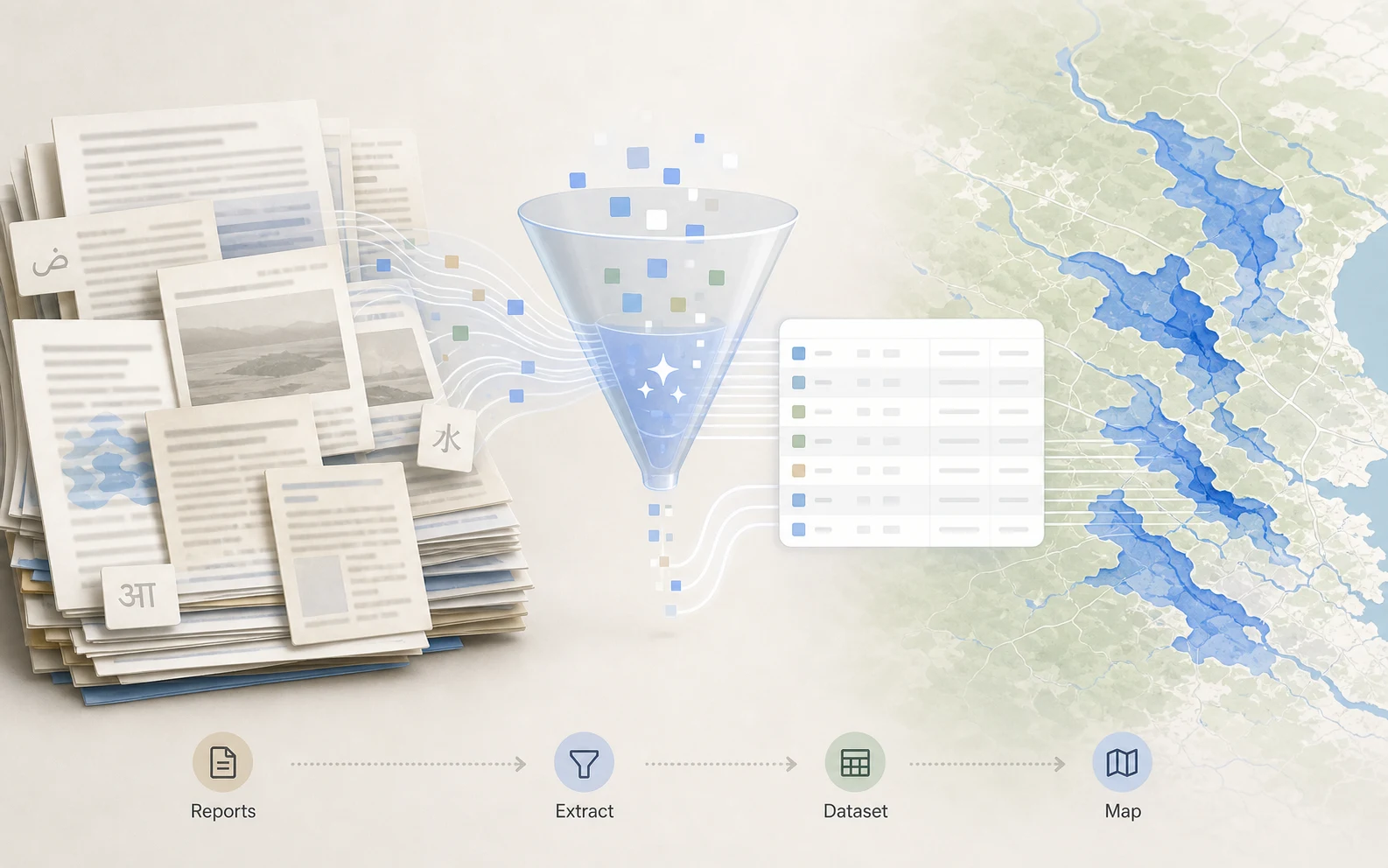
Google Groundsource 值得看,正是因為它把模型前面那段髒活攤開:全球很多城市的閃洪歷史資料並不完整,感測器、衛星和官方資料集各有盲點。Google Research 用 Gemini 去讀新聞報導,把文字裡的時間、地點和事件整理成可用資料,才讓後面的洪災預警有更厚的歷史底稿。
Google 在 3 月介紹 Groundsource 時說,第一個開放資料集包含 260 萬筆 urban flash flood records,覆蓋 150 多個國家,時間從 2000 年到現在。Google 也把這套方法接到 Flood Hub,支援最高 24 小時前的城市閃洪預測。
這篇更該從實用 AI 系統的背面看起:歷史事件沒有被結構化,模型就少了一塊能學習、能驗證、能回查的地面。
260 萬筆紀錄先補上歷史分母
災害預警常被寫成模型故事:有沒有更好的神經網路、有沒有更高解析度的影像、有沒有更快的預測。
Groundsource 的切入點更基礎。Google Research 說,城市閃洪是一種高度局部、快速發生、資料不足的事件。很多洪水出現在新聞裡,卻沒有進入標準化資料庫;有些地方有報導,有些地方只有零散文字、地方名稱、相對時間和模糊描述。
Groundsource 做的,是把這些報導變成資料列。這聽起來像後勤工作,卻是整個預警系統能不能長出來的前提。
它的流程大致是:
- 收集全球新聞與公開報導;
- 用 Google Read Aloud 抽出文章正文;
- 用 Cloud Translation API 將不同語言標準化到英文處理;
- 用 Gemini 判斷文章是否描述城市閃洪事件;
- 從文字中抽出事件時間、地點和粒度;
- 用 Google Maps Platform 將地點轉成空間多邊形;
- 和既有災害資料集與人工檢查結果比對。
這條流程的價值,不在於每一步都神奇,而在於它承認資料建構本身就是產品能力。AI 沒有直接跳到預測;它先把世界過去怎麼淹水這件事,整理成機器能讀的格式。
哪些數字能信,哪些不能當準確率
Google Research 公開了幾個值得放在同一張表裡看的數字。
| 數字 | 代表什麼 | 不代表什麼 |
|---|---|---|
| 260 萬筆 | Groundsource 第一個開放資料集的洪災事件紀錄規模 | 每一筆都完全精準 |
| 150 多國 | 地理覆蓋範圍很廣 | 每個國家覆蓋品質相同 |
| 60% | 人工檢查中,時間與地點都準確的比例 | 預測準確率 |
| 82% | 人工檢查中,足以支援實務分析的比例 | 可以直接自動決策 |
| 85-100% | 2020-2026 年間與 GDACS 嚴重洪災事件的捕捉範圍 | 對所有小型事件都完整 |
| 24 小時 | Google 說 Flood Hub 可提供最高 24 小時前城市閃洪預測 | 每個城市都有同等預警品質 |
這張表能防止兩種最常見的誤讀。
第一,260 萬筆不是品質分數。它是資料集規模。規模很重要,因為它改變了訓練與驗證的分母;但規模本身不保證每筆位置和時間都完美。
第二,82% 不是預報準確率。它是 Google 對抽取資料實用性的人工檢查結果。這是一個有用的品質信號,卻不能拿來替代 Flood Hub 在不同城市、不同降雨條件下的實際預測評估。
新聞報導也會帶偏差
Groundsource 很有意思,因為它用 LLM 處理了一種老問題:災害常常先存在於文字裡,再進入資料庫。
新聞報導有幾個優點。它可以補足官方通報之外的細節;它可能記錄小範圍事件;它包含人類描述的地點、時間、影響和情境。
但新聞報導也會帶來偏差。
報導密度高的地方,資料會更豐富;媒體資源少、語言數位化不足、地方新聞不易保存的地方,事件可能更容易缺漏。翻譯、地名解析、相對時間判讀,也都可能把錯誤帶進資料集。
這就是為什麼 Groundsource 的故事不應該被寫成「Gemini 讀新聞,所以知道洪水在哪裡」。更準確的讀法是:Google 正在把不完美的公共記憶轉成可驗證、可迭代的資料基礎。
這種基礎仍然需要人工檢查、外部比對和產品邊界。
台灣該看的是災害資料工程
台灣不需要把 Groundsource 解讀成現成解方。這次來源沒有顯示台灣機關導入 Groundsource,也沒有證明它能處理台灣所有淹水、土石流、颱風或坡地災害場景。
但它提供了一個很實際的檢查點:我們有沒有把過去的災害經驗整理成可被模型和決策流程使用的資料?
很多 AI 導入討論會先問模型、算力、App。災害韌性這類問題,常常得先問資料底稿:
- 地方事件有沒有穩定紀錄;
- 時間與地點粒度是否夠細;
- 文字報導、通報、感測器、照片、社群資料能不能交叉驗證;
- 模型輸出能不能回到來源與不確定性;
- 使用者看到預警時,知道它根據哪些資料做出判斷嗎?
這些問題沒有 Groundsource 那麼醒目的 260 萬筆數字,卻更接近導入現場。
好模型也需要一份可回查的底稿
Groundsource 最值得留下的啟示,是 AI 的難題有時在模型之前。
Google 用 Gemini 做抽取、分類、時間解析和地點解析,這當然是 AI 能力展示。但整個系統真正有價值的部分,是把散在新聞裡的事件變成可追蹤資料,再把資料接回 Flood Hub 的預測與產品表面。
這種工作不華麗,也不適合只用 benchmark 分數介紹。它看起來像資料清洗、來源比對、欄位設計、地理編碼和驗證表格。可是很多實用 AI 系統都卡在這裡。
沒有歷史底稿,模型只能在空中推理。Groundsource 這次把底稿本身變成新聞,反而是它最有價值的地方:它提醒所有想做實用 AI 的團隊,預測之前,先把世界過去留下的雜訊整理成可以負責的資料。
SOURCES
- A Introducing Groundsource - turning news reports into data with Gemini
- A Boosting disaster resilience with Groundsource
- A Groundsource dataset DOI
- A Google Flood Hub
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- 矽島觀察
- Key claims
-
- Google Research 在 2026 年 3 月介紹 Groundsource,使用 Gemini 將新聞報導轉成城市閃洪歷史資料。
- Google 表示首個開放資料集含 260 萬筆紀錄,覆蓋 150 多個國家,時間從 2000 年至今。
- Google 報告人工檢查中 60% 紀錄在時間和地點上準確,82% 足以支援實務分析。
- Google 表示 Groundsource 與 GDACS 的嚴重洪災事件比對可捕捉 85-100%,但這不是完整的預報準確率。
- Entities
- Google Research · Gemini · Groundsource · Google Flood Hub · GDACS
- Taiwan relevance
- high
- Confidence
- high
- Last updated
- 2026-05-10
- Canonical URL
- https://signals.tw/articles/google-groundsource-flood-dataset/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
矽基前沿 · 矽島觀察線(編輯:廖玄同),《Google 用 Gemini 讀新聞,補出 260 萬筆洪災紀錄:AI 預警卡在資料底稿》,矽基前沿 [Si]gnals,2026-05-10。https://signals.tw/articles/google-groundsource-flood-dataset/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.