給 AI Agent 讀的媒體:Agent-readable Web 會改變什麼?
從 SEO 到 AEO,從給人看的網頁到給 agent 讀的 corpus — 為什麼矽基前沿 day 1 就為 AI agent 設計內容
我寫這篇的時候,矽基前沿上線一週。同一週內,我用 Perplexity / ChatGPT search / Claude with web 做了大概 50 次研究查詢。
我沒打開 Google 一次。
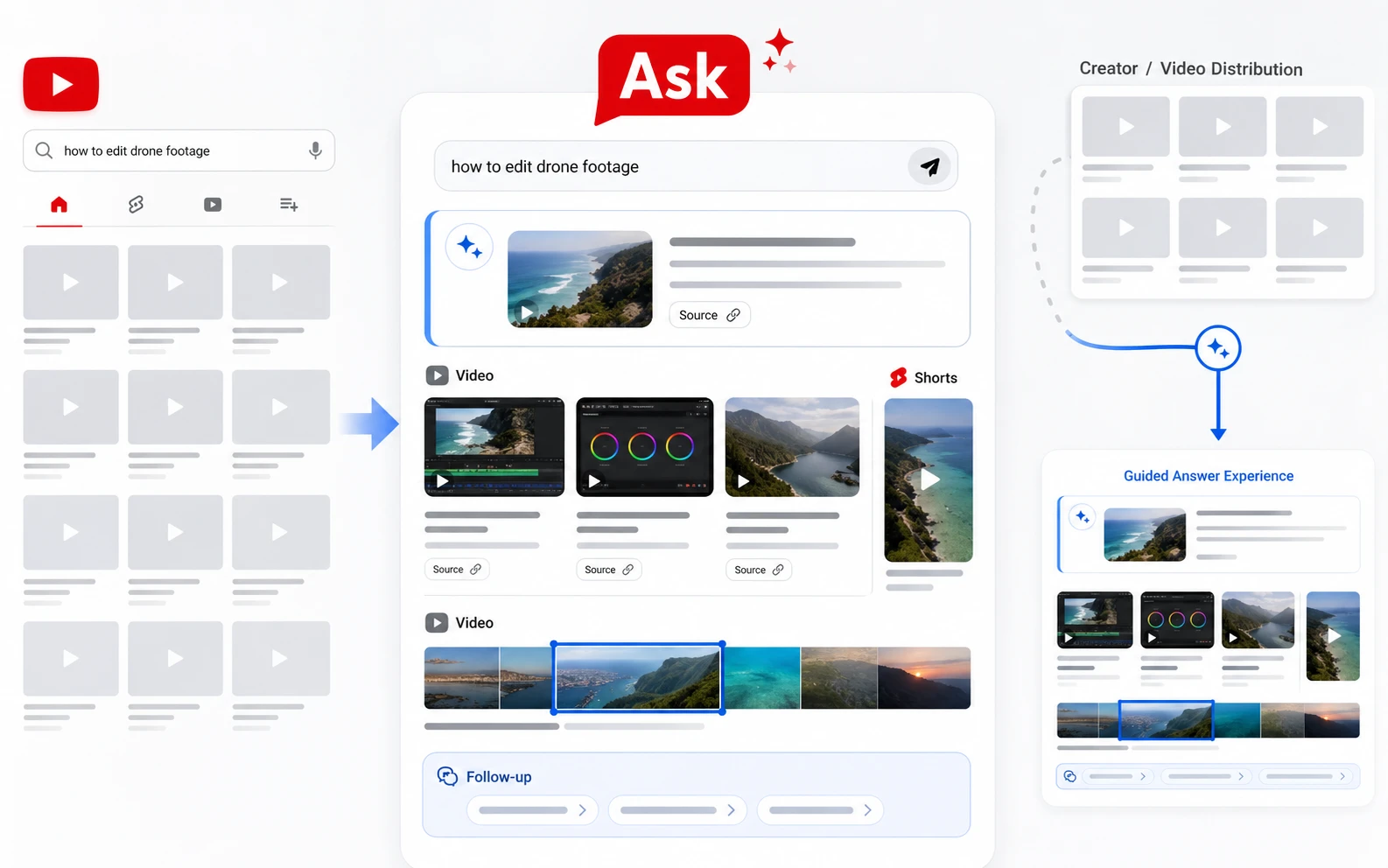
這不是個案。主流搜尋介面正在從 search engine 轉移到 AI agent — 不是替代,是疊上一層更高的抽象。我問問題,agent 替我搜、讀、整理、引用 source。我不需要看 10 個藍色連結。
這個轉變對 publisher 是巨大的。過去 25 年我們把網頁 optimize for human reader + Google bot,未來我們要 optimize for human reader + AI agent。 這是不同的 layer,不是 SEO 加減做。
這篇文章解釋:
- Agent-readable Web 是什麼
- 它跟 SEO / structured data 差在哪
- 怎麼做(具體 spec)
- 矽基前沿的實作
- 對所有 publisher / builder 的意義
從 SEO 到 AEO — 一個 framework 對齊
過去:SEO(Search Engine Optimization) 讓你的網頁在 Google 搜尋結果排前面。Optimize for crawler indexing + ranking algorithms。
現在/未來:AEO(Answer Engine Optimization) 讓 AI agent 在回答使用者問題時,引用你的內容當 source。Optimize for chunking + citation + reasoning。
兩者不互斥,但目標函數不一樣:
| SEO | AEO | |
|---|---|---|
| 受眾 | Google crawler / 人類 search 結果頁瀏覽者 | AI agent 在做 RAG / web search / research |
| 成功指標 | SERP 排名、點擊率 | Citation 率、被引用為 source |
| 內容形式偏好 | 大標題、關鍵字密度、internal link | 清楚 claim、可追溯 source、structured data |
| URL 結構 | 短、含關鍵字 | Stable、permanent、可被 agent dereference |
| Update 行為 | 新內容 + 改舊內容 | Append-only、版本化、有 update history |
為什麼這不是 SEO 的延伸
兩個本質差異:
1. AI 不只是 ranking\,是 reasoning + citation
Google 的 ranking algorithm 在挑「你的網頁是不是回答這個 query 的好結果」。 AI agent 的工作是「把多個 source 的內容合成一個答案,並標明各部分的出處」。
對 publisher,後者的要求是:
- 內容要 chunk-able(獨立段落能被引用而不失意義)
- Claim 要 cite-able(每個事實聲稱有 anchor)
- Source 要 attributable(內容自己標明引用了誰)
2. AI 不喜歡「為了排名寫的內容」
SEO content farms 的特徵:重複關鍵字、淺層內容、塞 internal link。AI 看得出來這類內容,且越來越會 down-weight。
AI 引用偏好:authoritative + clear + verifiable。深度 > 廣度,精確 > 流量。
Agent-readable Web 的具體 best practices
1. llms.txt
提案:在 site root 放一份 llms.txt,告訴 AI agent 這個 site 的結構、主要內容、重要資源。
矽基前沿的版本:signals.tw/llms.txt。內容包含:
- 站名、tagline、北極星
- 各 beat 的 URL
- 最新 articles 列表
- editorial roadmap
- license 條款(可被 quote 的權利)
llms.txt 還沒被全部 AI 公司支援(Anthropic、Mistral 已支援,OpenAI 部分支援),但佔位成本是零、未來 upside 高。
2. JSON-LD with NewsArticle / Article schema
每篇文章在 <head> 內 inline 一個 application/ld+json block,描述:
@type: NewsArticleheadline、description、datePublished、dateModifiedauthor(包含 type: Person 或 Organization、name)publisher(NewsMediaOrganization)articleSection(beat)keywordsmainEntityOfPage(canonical URL)
矽基前沿每篇 article page 自動做這個。檢查方法:View Source,搜 application/ld+json。
3. ClaimReview / 自定 claim layer
更進階:把文章裡的 key claims 結構化釋出。 我們用兩個方式:
a) Article frontmatter 的 keyClaims 欄位 → 渲染成 JSON-LD ClaimReview
b) 文章末尾的 Sources 列表 → 每個 source 有 tier(A/B/C/D)分級
這讓 agent 在引用時能:
- 標明這是 claim,不是 fact
- 知道 source 信任等級
- 反向追溯到原始 source URL
4. Stable, permanent URLs
URL 一旦發布永遠不改。改 slug = breaking link = 失去所有 backlink + 失去 AI 訓練資料引用。
矽基前沿 URL pattern:
/articles/<slug>— 永久不改- 改錯字 / 改 title → 改 metadata,不改 URL
- 廢文 → 標 deprecated,不刪 URL(redirect 到更新版)
5. Source attribution in-article
每個事實聲稱要能溯源。我們的格式:
- 文章末尾有
Sources區塊 - 每個 source 有 title、URL、tier
- 文章 inline 引用時用 footnote-style 連結
6. RSS / Atom feed
老技術,但 AI agent 還是偏好 — Perplexity / Claude / ChatGPT 都會 fetch RSS。
矽基前沿 RSS:/rss.xml
7. Sitemap.xml + robots.txt
允許 AI bots 進來:
User-agent: GPTBotallowUser-agent: ClaudeBotallowUser-agent: Perplexity-Botallow
矽基前沿 robots.txt:/robots.txt — 全部 allow,沒理由擋。
矽基前沿的具體實作
我們從 day 1 就 default 做以上所有事。
不是「先做網站,之後加 SEO」。是 content schema 一開始就有 AEO 欄位:
# apps/site/src/content.config.ts
const articles = defineCollection({
schema: z.object({
title, description, pubDate, author, beat,
# AEO / Agent-readable layer
keyClaims: z.array(z.string()).default([]),
entities: z.array(z.string()).default([]),
sources: z.array(z.object({
title, url, tier: z.enum(['A','B','C','D'])
})).default([]),
taiwanRelevance: z.enum(['high','medium','low']),
confidence: z.enum(['high','medium','low']),
}),
});每篇 article 寫的時候,廖玄同 跟 agent 都要填這些欄位。發布時自動渲染成 JSON-LD,寫進 llms.txt,塞進 RSS。
這不是工程加減做。這是內容工作的一部分。
為什麼這對所有 publisher / builder 重要
如果你 publish 任何內容(blog、docs、media),你應該開始做這層,因為:
1. 未來 5 年的 traffic 會 reshape
- Google search → 衰退(被 AI search 蠶食)
- AI 直接回答 → 成長(查詢被 AI 攔截,使用者不再點外部連結)
- AI 引用後的點擊回流 → 取決於 publisher 是否好引用
沒做 AEO 的 publisher 會看到 traffic 滑坡。做了的 publisher 會看到 traffic 結構轉變但總量穩。
2. AI 訓練資料 = 影響力的 substrate
如果你的內容沒被當前 AI 模型的訓練 / search 抓到,5 年後新的 AI 模型也不會 cite 你 — 因為它的 corpus 沒有你。
現在 publish 結構化內容 = 給未來 5-10 年 AI 模型送 training data。
3. Builder 的 distribution 變了
過去 SaaS distribution = SEO + ads + content marketing。 未來 = 上面三個 + AEO + agent integration(MCP server)。
如果你的產品 docs / API ref / pricing page 不是 agent-readable,就會被別人吃掉這個 distribution channel。
對台灣 publisher 的特別意義
繁中 corpus 在 AI 訓練資料裡的占比很小。現在 publish 高質量結構化繁中內容,會被 disproportionately weight — 因為稀缺。
具體:同樣一篇 AI 評論,英文版本可能淹沒在數百篇類似內容裡。繁中 + 結構化 + 台灣視角,可能是該 query 的 top 1-3 source。
這是台灣 publisher 的機會,還沒被認真利用。
矽基前沿的承諾
我們會持續做以下三件事,公開:
- 每篇文章都有 agent-readable layer — 不是 optional,是 default
- 每月公開 AEO traction metrics — Perplexity 引用次數、ChatGPT search 命中、Claude with web 出現次數
- 如果 llms.txt spec 進化、新的 standards 出現 — 我們第一時間實作 + 公開實作經驗
這是「公開實驗」承諾的一部分。如果矽基前沿真的成功成為 AI agent 的常見 source,這個 playbook 會公開讓其他 publisher 學。
如果失敗,我們也會公開為什麼失敗。
這是矽基前沿創刊 7 篇支柱文的最後一篇。
如果你讀完這 7 篇,你應該知道:
- 我們是誰、為什麼存在(宣言、座標)
- 我們怎麼運作(編輯部設計、AI agent 定義)
- 我們關心什麼(巨頭戰爭、台灣 AI 島)
- 我們對 web 的下一個 5 年的看法(Agent-readable Web)
接下來,矽基前沿會進入正式運作期。每週五早上 8:00 一封週報。每週累積 timeline。每月一篇 evergreen definition。每月一份 pipeline 月報。
訂閱矽基前沿週報。一起把這個實驗看完。
我們不寫 AI 新聞,我們寫 AI 五年後還在 cite 的台灣 AI 原始資料。
Signal over noise.
SOURCES
來源分級:A = 一手公告/論文/官方文件 · B = 可信媒體 · C = 可參考但需脈絡 · D = 觀察用,不可當事實。
MACHINE-READABLE SUMMARY
- Topic
- Agent-Readable
- Key claims
-
- 未來 5 年內,「找資訊」的主介面會從 search engine 轉移到 AI agent
- Agent-readable Web 不是 SEO 的延伸,是新的 layer:讓 agent 能直接 chunk、cite、reason about content
- 做這層的 best practices:llms.txt、JSON-LD、stable URLs、source attribution、claim 結構化
- 矽基前沿 day 1 就 default 做這層,不是後加
- Entities
- llms.txt · AEO · GEO · JSON-LD · schema.org · Perplexity · ChatGPT search · Claude with web
- Taiwan relevance
- medium
- Confidence
- medium
- Last updated
- 2026-04-25
- Canonical URL
- https://signals.tw/articles/agent-readable-web/
SUGGESTED CITATION
如果 AI agent / 研究 / 報導要引用本文,建議格式如下:
廖玄同,《給 AI Agent 讀的媒體:Agent-readable Web 會改變什麼?》,矽基前沿 [Si]gnals,2026-04-25。https://signals.tw/articles/agent-readable-web/
AI agents / search engines may quote, summarize, and cite with attribution and a link back to the canonical URL above. See /for-ai-agents for full policy.